Hybrid Search for RAG: Combining BM25 and Dense Vector Search (2026 Guide)

TL;DR: Hybrid search combines sparse keyword retrieval (BM25) with dense vector search, fused via Reciprocal Rank Fusion (RRF). On the WANDS e-commerce benchmark, a tuned hybrid setup reaches 0.7497 NDCG — a 7.4% lift over either BM25 (0.6983) or pure vector search (0.6953) alone (Turnbull, 2025). On financial documents with mixed text and tables, a two-stage hybrid + neural reranking pipeline achieves Recall@5 of 0.816 (Strich et al., 2026). If your RAG system uses pure vector search, adding BM25 is the single highest-impact retrieval upgrade you can make.
| Approach | Strength | Weakness | NDCG (WANDS) |
|---|---|---|---|
| BM25 only | Exact-match precision (SKUs, codes, names) | No semantic understanding | 0.6983 |
| Dense vector only | Semantic paraphrase matching | Misses rare exact terms | 0.6953 |
| Hybrid (RRF) | Combines both, fills blind spots | Slightly more infrastructure | 0.7068 |
| Hybrid + field boosting | Best accuracy | Requires tuning | 0.7497 |
Read on for the architecture, fusion algorithms, code examples, benchmark data, and a tuning framework you can apply to your own RAG pipeline.
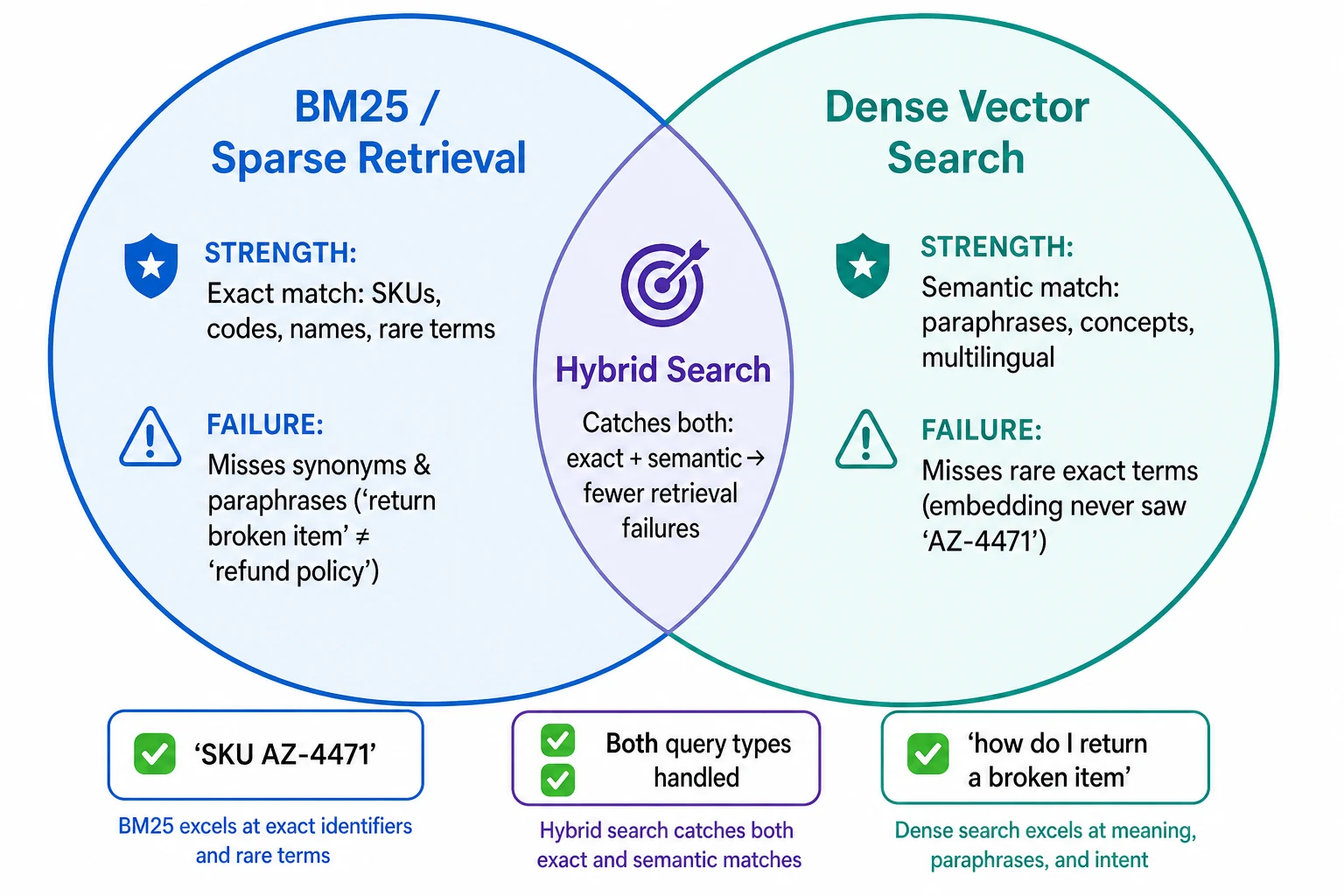
Why Pure Vector Search Is Not Enough#
Your RAG chatbot returns the wrong product. A customer types "SKU AZ-4471" and the bot confidently describes a different item — one that is semantically related but is not the product they asked about. The document containing "AZ-4471" is in the knowledge base. The retriever never surfaced it.
This is the dense-only retrieval failure mode. Vector embeddings encode meaning, not exact strings. When a query contains a rare identifier — a product code, an error number, a regulatory clause reference, a person's name — the embedding model may never have seen that token during training. The query vector lands somewhere generic in embedding space, and the exact-match document that contains the literal string gets out-ranked by semantically similar but incorrect passages.
The reverse failure is just as common. A user asks "how do I return a damaged item?" and the knowledge base article is titled "Refund Policy for Defective Products." No words overlap. BM25 returns nothing useful because it matches tokens, not meaning. A dense retriever finds it instantly because the embeddings capture the semantic equivalence.
Neither approach wins across all query types. This is not a theoretical concern — it is the most common retrieval quality problem in production RAG systems. The fix is hybrid search: run both retrieval methods and fuse their results. For the broader RAG architecture that retrieval fits into, see our guide: What Is RAG? (Retrieval-Augmented Generation Explained).
What Is BM25 (Sparse Retrieval)?#
BM25 (Best Matching 25) is a probabilistic retrieval algorithm developed by Stephen E. Robertson and Karen Spärck Jones at City University London in the 1980s–90s. It scores documents based on how well their terms match the query. It is the backbone of every major search engine — Elasticsearch, OpenSearch, Solr, Lucene — and has been the production standard for keyword search since the 1990s.
How BM25 Works#
BM25 builds an inverted index: for every term in your corpus, it stores a list of documents containing that term along with the term's frequency in each. At query time, it looks up each query term, scores each candidate document, and ranks the results.
The scoring formula has two key mechanisms:
- Term frequency saturation: Additional occurrences of a term contribute less and less to the score. A document mentioning "refund" ten times is not ten times more relevant than one mentioning it once — the score saturates, preventing keyword stuffing from dominating results.
- Length normalization: Longer documents are penalized to prevent volume-driven score inflation. A 5,000-word document that mentions "refund" twice should not outrank a 200-word document that mentions it twice.
BM25 has two tunable parameters:
| Parameter | Default | What It Controls |
|---|---|---|
| k1 | 1.2 | Term frequency saturation. Higher (toward 2.0) rewards repeated terms more. |
| b | 0.75 | Length normalization. 1.0 = full penalty for long docs; 0 = no penalty. |
The defaults (k1=1.2, b=0.75) work well for general text. For short, structured documents like product catalogs, lowering k1 to 0.5–0.8 often improves precision. For long-form documents where term repetition is meaningful (research papers, legal contracts), raising k1 toward 1.5–2.0 helps.
Where BM25 Excels#
- Exact-match queries: Product SKUs, error codes, version numbers, person names, regulatory references
- Out-of-vocabulary terms: Terms the embedding model has never seen — BM25 matches them as long as they appear in the index
- High-throughput retrieval: BM25 requires no neural inference at query time. It runs on CPU using the inverted index, making it fast and cheap at scale
Where BM25 Fails#
- Synonym and paraphrase queries: "automobile repair" will not match "car maintenance"
- Conceptual queries: "how to cancel" will not match a page titled "subscription termination process"
- Multilingual matching: BM25 is language-specific and cannot bridge languages
What Is Dense Vector Search (Dense Retrieval)?#
Dense vector retrieval maps text into a high-dimensional embedding space using a neural encoder — a sentence transformer or embedding model from providers like OpenAI, Cohere, Voyage AI, or open-source models like BGE and E5. Both the query and every document chunk are encoded into vectors, and retrieval becomes a similarity search: find the top-k documents whose vectors are closest to the query vector under cosine similarity or dot product.
Because exact nearest-neighbor search across millions of vectors is too slow for query-time latency, production systems use Approximate Nearest Neighbor (ANN) indexes. The dominant index type is HNSW (Hierarchical Navigable Small World), a graph-based index used by Qdrant, Weaviate, and Pinecone. HNSW trades a small recall loss for dramatically faster search.
For a deeper explanation of how embeddings power retrieval, see our guide to semantic search. For embedding model selection, our comparison of open-source vs paid embedding models covers the tradeoffs.
Where Dense Retrieval Excels#
- Semantic matching: "how do I get my money back" matches "refund policy" with no shared words
- Paraphrase and conceptual queries: Handles natural language the way users actually type it
- Multilingual matching: Cross-lingual embedding models can match a query in English to documents in Spanish
Where Dense Retrieval Fails#
- Rare exact terms: If the embedding model has never seen "AZ-4471" during training, the query vector carries little signal for that specific product
- Numerical precision: "revenue grew 3.2%" and "revenue grew 3.7%" produce nearly identical embeddings — the semantic meaning is the same, but the numbers are critically different
- Domain-specific terminology: General-purpose embeddings may not represent specialized vocabulary accurately
Why Neither Wins Alone: The Complementary Failure Modes#
The key insight is that BM25 and dense retrieval fail in complementary ways. Each method fills the other's blind spot:
| Query Type | BM25 | Dense | Who Wins |
|---|---|---|---|
| "SKU AZ-4471" | ✅ Exact match | ❌ Rare term, weak embedding | BM25 |
| "how do I return a broken item" | ❌ No keyword overlap | ✅ Semantic match to "refund policy" | Dense |
| "What is the return policy?" | ✅ Matches "return policy" | ✅ Semantic match | Both |
| "error code ERR_4021 fix" | ✅ Matches error string | ❌ Rare identifier | BM25 |
| "best practices for onboarding" | ❌ Vague, no specific terms | ✅ Conceptual match | Dense |
A 2026 benchmark on financial documents with mixed text and tables confirmed this pattern empirically: BM25 outperformed state-of-the-art dense retrieval on financial documents, challenging the common assumption that semantic search universally dominates. The reason is precise — financial documents are full of identifiers, numbers, and exact terminology that dense embeddings smooth over (Strich et al., 2026).
The answer is not to pick one. The answer is to run both and fuse.
How Hybrid Search Works: The Three-Stage Pipeline#
A production hybrid search pipeline has three distinct stages. Understanding which concerns belong to which stage determines both quality and cost.
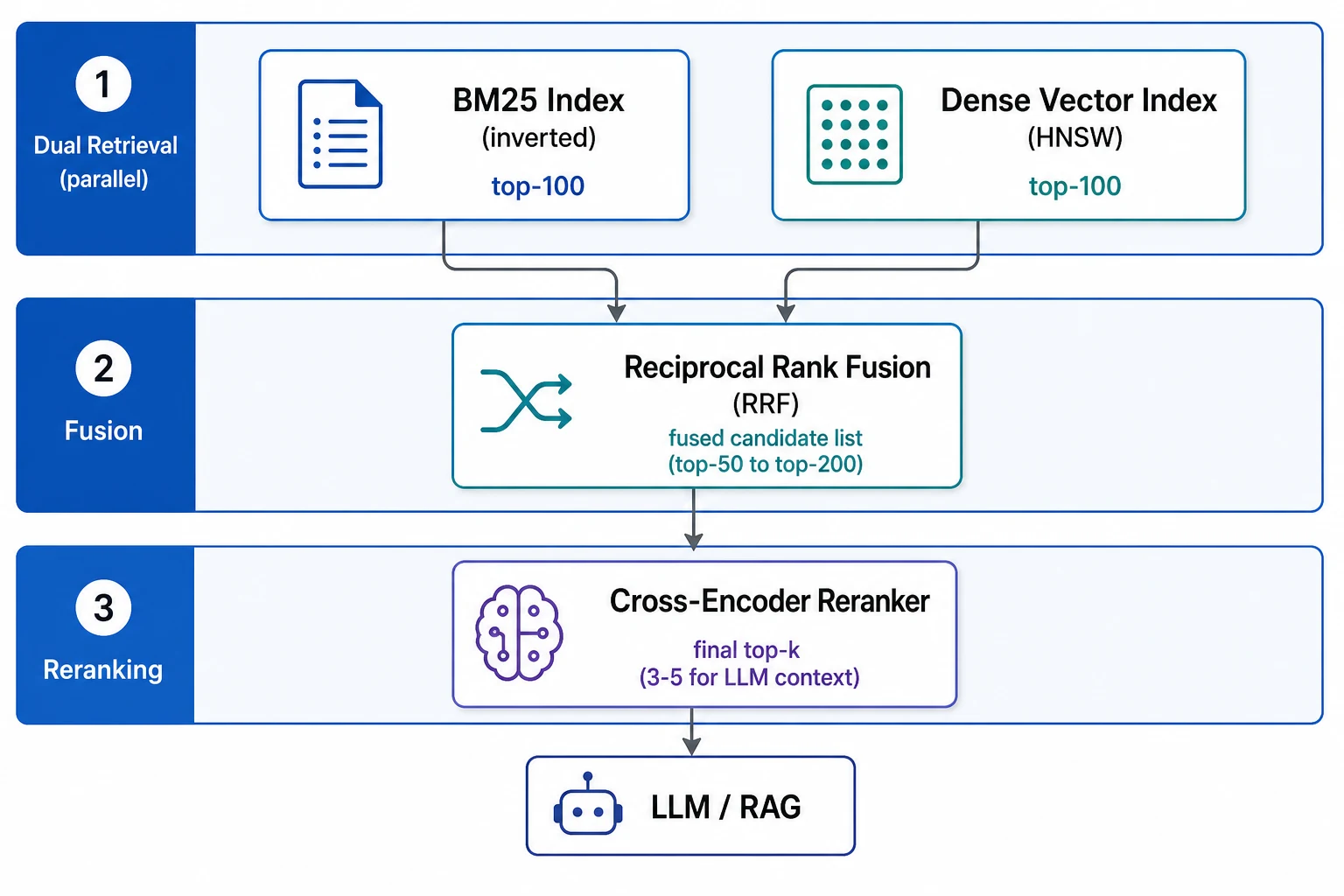
Stage 1 — Dual Retrieval#
Query both the sparse (BM25) and dense (ANN) indexes in parallel. Each returns a ranked candidate list — typically top-50 to top-500 per retrieval mode depending on your reranking budget. Running them in parallel keeps latency roughly the same as a single retrieval call.
Stage 2 — Fusion#
Merge the two ranked lists into a single ranking. This is where the fusion algorithm matters. Naively averaging BM25 scores with cosine similarity scores fails because the two scoring scales are incompatible — BM25 scores are unbounded positive numbers, while cosine similarity ranges from -1 to 1. The standard solution is Reciprocal Rank Fusion (RRF), which operates on ranks, not scores.
Stage 3 — Cross-Encoder Reranking#
Take the top-N from the fused list (N typically 50–200) and pass each (query, document) pair to a cross-encoder reranker. Unlike bi-encoder embedding models that encode query and document independently, a cross-encoder sees both simultaneously — allowing it to model fine-grained semantic relationships that embedding-space proximity misses. Return the final top-k (typically 3–5 chunks) as context for the LLM.
Reciprocal Rank Fusion (RRF) Explained#
RRF was introduced by Gordon Cormack, Charles Clarke, and Stefan Buettcher at the University of Waterloo in their 2009 SIGIR paper "Reciprocal Rank Fusion outperforms Condorcet and individual Rank Learning Methods" (Cormack et al., 2009). The algorithm is deliberately simple: for each document, sum the reciprocal of its rank position across all result lists, dampened by a constant k.
The Formula#
score(d) = Σ 1 / (k + rank(d))
Where:
- k is a ranking constant (default 60 in Elasticsearch and most implementations)
- rank(d) is the 1-indexed rank of document d in each result list
- Raw scores are ignored entirely — only rank positions contribute
This is the critical design decision. By ignoring raw scores, RRF eliminates the BM25-vs-cosine incompatibility problem without any normalization step. A document at rank 1 in the BM25 list and rank 3 in the dense list gets 1/61 + 1/63 = 0.0323 — a simple, comparable score.
Why k = 60#
The rank constant k = 60 means a document at rank 1 contributes 1/61 ≈ 0.0164 per list, while one at rank 100 contributes 1/160 ≈ 0.00625 — a 2.6× difference. Higher k dampens the influence of top-ranked documents and gives more weight to documents that appear consistently across many lists, even at moderate rank positions.
As the Elasticsearch documentation notes, citing the original Cormack paper: "RRF requires no tuning, and the different relevance indicators do not have to be related to each other to achieve high-quality results."
RRF vs. Weighted Score Combination#
| Fusion Method | How It Works | Problem |
|---|---|---|
| Weighted average | α × BM25_score + (1-α) × cosine_score | Scores are incompatible scales — requires normalization, tuning |
| RRF | Sum 1/(k + rank) across lists | No normalization needed, no tuning required, robust default |
Weighted score combination can work, but it requires you to normalize scores and tune the alpha parameter for your specific corpus. RRF works out of the box. Start with RRF; switch to weighted fusion only if you have an evaluation harness that proves a tuned alpha beats RRF on your data.
Hybrid Search Code Examples#
Example 1: RRF From Scratch (Python)#
If you are running BM25 and dense retrieval separately and fusing client-side, RRF is trivial to implement:
def reciprocal_rank_fusion(
bm25_results: list[str],
dense_results: list[str],
k: int = 60,
top_n: int = 10
) -> list[tuple[str, float]]:
"""
Fuse two ranked result lists using Reciprocal Rank Fusion.
Args:
bm25_results: List of document IDs ranked by BM25 (best first)
dense_results: List of document IDs ranked by dense retrieval
k: Ranking constant (default 60, per Cormack et al. 2009)
top_n: Number of fused results to return
Returns:
List of (doc_id, rrf_score) tuples, highest first
"""
rrf_scores = {}
for rank, doc_id in enumerate(bm25_results, start=1):
rrf_scores[doc_id] = rrf_scores.get(doc_id, 0) + 1 / (k + rank)
for rank, doc_id in enumerate(dense_results, start=1):
rrf_scores[doc_id] = rrf_scores.get(doc_id, 0) + 1 / (k + rank)
# Sort by fused score, descending
fused = sorted(rrf_scores.items(), key=lambda x: x[1], reverse=True)
return fused[:top_n]
# Example usage
bm25_hits = ["doc_42", "doc_17", "doc_8", "doc_91", "doc_3"]
dense_hits = ["doc_8", "doc_42", "doc_55", "doc_17", "doc_99"]
fused = reciprocal_rank_fusion(bm25_hits, dense_hits, k=60, top_n=5)
for doc_id, score in fused:
print(f"{doc_id}: RRF score = {score:.6f}")Output:
doc_42: RRF score = 0.032520 (rank 1 in BM25, rank 2 in dense)
doc_8: RRF score = 0.031885 (rank 3 in BM25, rank 1 in dense)
doc_17: RRF score = 0.030675 (rank 2 in BM25, rank 4 in dense)
doc_55: RRF score = 0.016393 (rank 3 in dense only)
doc_91: RRF score = 0.016129 (rank 4 in BM25 only)
Notice what happens: doc_42 and doc_8 both appear in both lists, so they get boosted above documents that appear in only one list. This is the core value of RRF — it rewards consensus across retrieval methods.
Example 2: Hybrid Search with Qdrant (Native RRF)#
Qdrant added server-side hybrid fusion in v1.10 via the Query API, eliminating client-side merging:
from qdrant_client import QdrantClient
from qdrant_client.models import (
FusionQuery,
Fusion,
SparseVectorParams,
SparseIndices,
VectorParams,
Distance,
)
client = QdrantClient(host="localhost", port=6333)
# Create a collection with both dense and sparse vectors
client.create_collection(
collection_name="hybrid_docs",
vectors_config={
"dense": VectorParams(size=1536, distance=Distance.COSINE),
},
sparse_vectors_config={
"sparse": SparseVectorParams(),
},
)
# Query with native RRF fusion
results = client.query_points(
collection_name="hybrid_docs",
prefetch=[
# Dense retrieval stage
{
"using": "dense",
"query": dense_query_vector, # your embedded query
"limit": 50,
},
# Sparse (BM25) retrieval stage
{
"using": "sparse",
"query": SparseIndices(
indices=sparse_query_indices,
values=sparse_query_values,
),
"limit": 50,
},
],
# Fuse with RRF
fusion=FusionQuery(fusion=Fusion.RRF),
limit=10,
)
for point in results.points:
print(f"ID: {point.id}, Score: {point.score:.6f}")Example 3: Hybrid Search with Pinecone (Alpha-Weighted)#
Pinecone stores both dense and sparse vectors in a single index and uses an alpha parameter to weight them:
from pinecone import Pinecone
pc = Pinecone(api_key="your-api-key")
index = pc.Index("hybrid-docs")
# Alpha = 0.5 means equal weight to dense and sparse
# Alpha = 1.0 = pure dense, alpha = 0.0 = pure sparse
results = index.query(
vector=dense_query_vector, # 1536-dim dense embedding
sparse_vector={
"indices": sparse_indices, # BM25 sparse indices
"values": sparse_values,
},
top_k=10,
include_metadata=True,
alpha=0.5, # equal weight to both methods
)
for match in results["matches"]:
print(f"ID: {match['id']}, Score: {match['score']:.6f}")
print(f" Metadata: {match.get('metadata', {})}")Important caveat with alpha-weighted fusion: Without explicit alpha tuning, BM25 tends to dominate because its unbounded scores outweigh cosine similarity scores (which range from -1 to 1). If you use Pinecone's alpha-weighted approach, evaluate different alpha values (0.3, 0.5, 0.7) on your own query set and pick the one that maximizes retrieval quality.
Benchmark Data: How Much Does Hybrid Search Actually Improve RAG?#
All numbers below are drawn from published sources. We cite each benchmark to its original publication and note where figures are vendor-stated rather than independently replicated.
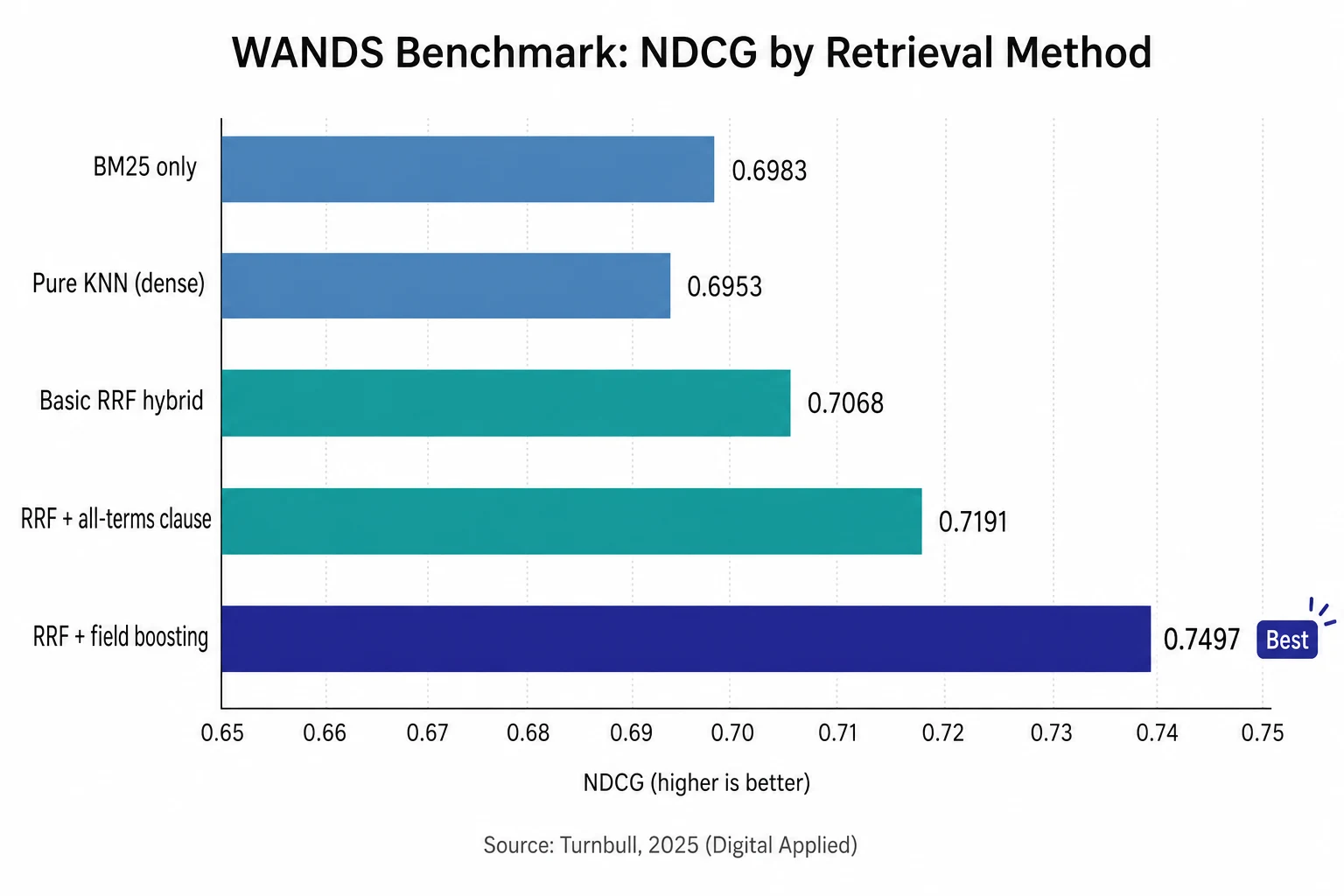
WANDS E-Commerce Benchmark (March 2025)#
Doug Turnbull's March 2025 study on the WANDS furniture e-commerce dataset provides the clearest apples-to-apples comparison (Turnbull, 2025):
| Retrieval Method | NDCG (mean) | NDCG (median) | vs. Best Single Method |
|---|---|---|---|
| BM25 only | 0.6983 | 0.7550 | — |
| Pure KNN (dense) | 0.6953 | 0.7500 | — |
| Basic RRF hybrid | 0.7068 | 0.7570 | +1.2% |
| RRF + all-terms clause | 0.7191 | 0.7750 | +3.0% |
| RRF + field boosting | 0.7497 | 0.8418 | +7.4% |
Key takeaways:
- BM25 and pure dense are statistically indistinguishable on this dataset (0.6983 vs 0.6953) — neither alone is clearly better. Note the single-dataset caveat: WANDS covers furniture e-commerce queries; performance on long-form technical documents or QA tasks will differ.
- Basic RRF immediately outperforms both, with zero tuning
- The biggest gains come from domain-aware tuning on top of the fused base — boosting the product name field lifts NDCG to 0.7497
Financial Document Benchmark (2026)#
A 2026 study by Strich et al. benchmarking ten retrieval strategies on 23,088 queries over 7,318 financial documents with mixed text and tables (T2-RAGBench, accepted at EACL 2026) found (Strich et al., 2026):
| Retrieval Strategy | Recall@5 | MRR@3 | nDCG@10 |
|---|---|---|---|
| Dense retrieval only (text-embedding-3-large) | 0.587 | 0.351 | 0.466 |
| BM25 only (k1=1.2, b=0.75) | 0.644 | 0.411 | 0.515 |
| Hybrid fusion only (RRF, k=60) | 0.695 | 0.433 | 0.551 |
| Hybrid + Cohere Rerank | 0.816 | 0.605 | 0.683 |
Two critical findings:
- BM25 outperformed state-of-the-art dense retrieval on financial documents — on every metric except Recall@20, BM25 (using OpenAI text-embedding-3-large, one of the strongest commercial embedding models in 2026) outperformed dense retrieval. This challenges the assumption that semantic search always wins.
- The two-stage hybrid + reranking pipeline outperformed all single-stage methods by a large margin — Hybrid + Cohere Rerank achieved a +17.4% relative Recall@5 improvement over hybrid RRF alone (0.816 vs 0.695), and +39.0% over dense-only (0.816 vs 0.587). All pairwise differences were statistically significant (p < 0.001, paired bootstrap test with B=10,000, Bonferroni-corrected). The combination of fusion and reranking is where the biggest gains live.
Denser Retriever on MTEB Retrieval Benchmark#
Denser Retriever, which combines dense vector search (Milvus) with sparse keyword retrieval (Elasticsearch) and an XGBoost ML reranker, was benchmarked across the MTEB retrieval datasets (Denser AI, 2024). Its best XGBoost combination model achieved an NDCG@10 of 56.47, surpassing the vector-search-only baseline (NDCG@10 of 54.24) — an absolute increase of 2.23 points and a relative improvement of 4.11%. While smaller in magnitude than the financial-document gains, this improvement was consistent across the full MTEB suite, demonstrating that combining keyword + vector + ML reranking outperforms pure vector search across diverse retrieval tasks.
Cross-Encoder Reranking: The Third Stage#
Hybrid search gets you a better candidate pool. Reranking gets you the best final ordering. The two work together: hybrid retrieval produces a top-100 fused list, and a cross-encoder reranker re-scores that shortlist to surface the top-3 to top-5 chunks that actually go to the LLM.
Why Reranking Helps#
Bi-encoder embedding models (the ones used for dense retrieval) encode the query and document independently. The query becomes a vector; the document becomes a vector; similarity is computed as the distance between them. This is fast but lossy — the model never sees the query and document together.
A cross-encoder sees both the query and document simultaneously, computing a joint relevance score. This allows it to model fine-grained relationships: does this specific passage actually answer this specific question? The trade-off is compute — cross-encoders scale as O(n) with candidate count, which is why they are used only on a shortlist, not the full index.
Leading Rerankers in 2026#
| Reranker | Context Window | Key Feature |
|---|---|---|
| Cohere Rerank 3.5 | 4K tokens | Production baseline, handles tables/JSON/code |
| Voyage rerank-2.5 | 32K tokens | Instruction-following — steer relevance with natural language |
| bge-reranker-v2 | 8K tokens | Open-source, self-hostable, strong on BEIR benchmarks |
Voyage rerank-2.5's instruction-following capability is worth highlighting. You can prepend natural language instructions to steer relevance: "prefer results that include regulatory references" or "prioritize technical specifications over marketing materials." This opens personalization paths that earlier cross-encoders could not offer. Note: Voyage reports +7.94% accuracy over Cohere Rerank v3.5 on 93 datasets — these figures are vendor-stated, not independently replicated (Voyage AI, 2025).
When to Skip Reranking#
Reranking adds 100–300ms of latency and cost per query. Skip it when:
- Your corpus is small (under 1,000 documents) and hybrid retrieval already achieves high precision
- Your latency budget is under 500ms total
- You are in prototyping phase — get hybrid retrieval working first, add reranking when you have an evaluation harness
When to Use Hybrid Search (and When Not To)#
Use Hybrid Search When#
- Your queries mix exact-match and conceptual intent. Most real-world RAG systems do. A customer support bot gets both "what is your return policy?" (semantic) and "order #ORD-78231" (exact match).
- Your corpus contains identifiers, codes, or specialized terminology. Product SKUs, error codes, regulatory clause numbers, medical codes — all are BM25 territory.
- Your documents are in a specialized domain. General-purpose embedding models underperform on domain-specific vocabulary. BM25 catches the terms the embeddings miss.
- You have numerical or tabular content. Dense embeddings smooth over small numerical differences; BM25 preserves them.
You May Not Need Hybrid Search When#
- Your queries are purely conversational. If users always ask in natural language with no identifiers or codes, dense-only may suffice. Benchmark both before deciding.
- Your corpus is small and uniform. Under 500 short documents with consistent vocabulary — the retrieval problem is simple enough that dense-only handles it.
- You cannot tolerate any additional latency. If you are already at your latency ceiling and cannot add a parallel retrieval call, stick with a single method and optimize it.
Even in these cases, the cost of testing hybrid search is low. Run BM25 alongside your existing dense retrieval, fuse with RRF, and measure. If it does not improve your retrieval metrics, you have lost a few hours — not weeks.
Implementation Across Vector Databases#
Each major platform exposes hybrid search differently. Here is how they compare:
| Platform | Fusion Method | Notes |
|---|---|---|
| Qdrant (v1.10+) | Server-side RRF | Native via Query API. Multi-stage pipelines: sparse + dense RRF, then optional ColBERT reranking. |
| Weaviate (v1.24+) | Relative Score Fusion (default) | Changed default from RRF to Relative Score Fusion in v1.24. Both available — specify fusionType explicitly. |
| Pinecone | Alpha-weighted linear | Single index stores both dense and sparse. alpha=0.5 = equal weight. Watch for BM25 score dominance without tuning. |
| Elasticsearch | Native RRF (Enterprise) | rrf retriever with rank_constant=60. Enterprise plan required. Free tier workaround: client-side RRF with the ranx library. |
The Weaviate v1.24 change deserves attention. Teams upgrading from an earlier version without explicitly setting fusionType will silently switch from RRF to Relative Score Fusion. Both work, but they produce different result orderings. If you have baseline evaluations to protect, always pin fusionType explicitly.
For teams comparing infrastructure options, our guides to Elasticsearch alternatives and Pinecone alternatives cover the broader landscape.
Tuning Hybrid Search: Best Practices#
1. Start with RRF at k = 60#
RRF with the default k = 60 is a reliable baseline that requires no tuning. Measure your retrieval quality (NDCG, MRR, or recall@k) on a representative query set, then iterate from there.
2. Adjust k Based on Your Precision Needs#
- k = 60 (default): Balanced. Good for general-purpose retrieval.
- k = 30–40: Favors top-1 precision. Documents that rank first in either list get more weight. Good for Q&A where the top result matters most.
- k = 80–100: Favors consensus. Documents that appear consistently across both lists get more weight, even at moderate ranks. Good for research tasks where breadth matters.
3. Tune BM25 Parameters for Your Corpus#
The Lucene defaults (k1=1.2, b=0.75) are a starting point, not a destination:
| Document Type | k1 | b | Why |
|---|---|---|---|
| General web/enterprise text | 1.2 | 0.75 | Lucene defaults, well-tested |
| Short structured docs (product cards) | 0.5–0.8 | 0.3–0.5 | Less term repetition, shorter docs |
| Long-form docs (papers, contracts) | 1.5–2.0 | 0.8–0.9 | Term repetition is meaningful |
| Mixed corpus | 1.2 | 0.75 | Stick with defaults, use field boosting instead |
4. Use Field-Level Boosting for Structured Documents#
If your documents have high-signal fields (product names, titles, section headers), boost those fields in the BM25 query. The WANDS benchmark showed that boosting the product name field lifted NDCG from 0.7191 to 0.7497 — the single biggest tuning gain in the study (Turnbull, 2025).
5. Always Evaluate on Your Own Data#
Vendor benchmarks and academic studies tell you what is possible. They do not tell you what will work on your corpus. Build an evaluation set of 50–200 representative queries with known relevant documents. Measure NDCG or MRR before and after each change. Without this, you are tuning blind.
How Chunking Interacts with Hybrid Search#
Hybrid search and chunking are interdependent. The chunking strategy determines what gets indexed in both the BM25 inverted index and the dense vector store. A chunk that splits a product name from its description hurts both retrieval methods — BM25 cannot match the full product name, and the dense embedding loses context.
For production hybrid search, recursive character splitting at 256–512 tokens is the most reliable default. It produces coherent chunks that work well for both sparse and dense retrieval. Semantic chunking can improve dense retrieval recall but sometimes produces chunks that are too small or too large for effective BM25 scoring.
For a complete breakdown of chunking strategies with benchmarks and code, see our guide: RAG Chunking Strategies: 8 Methods Compared.
How Denser Retriever Implements Hybrid Search#
Denser Retriever is the open-source retrieval engine that powers Denser AI. It implements the full three-stage hybrid pipeline out of the box:
- Stage 1 — Dual retrieval: Dense vector search (Milvus with snowflake-arctic-embed-m embeddings) runs in parallel with sparse keyword retrieval via Elasticsearch. Both retrieve from the same indexed corpus.
- Stage 2 — Fusion: Results are fused using a learned ranking model rather than pure RRF. A gradient-boosted model (XGBoost) combines the retrieval scores with document metadata features, producing a fused ranking that adapts to the specific corpus.
- Stage 3 — ML reranking: An XGBoost-based reranker re-scores the top candidates, producing the final ranking sent to the LLM.
On the MTEB retrieval benchmark, this approach achieved an NDCG@10 of 56.47 versus a pure vector search baseline of 54.24 — a 4.11% relative improvement, consistent across the full MTEB suite (Denser AI, 2024).
Denser Retriever is fully open source. The complete implementation lives on the Denser Retriever GitHub repository, so you can read exactly how dual retrieval, learned fusion, and ML reranking fit together — and self-host the engine with full control.
If you would rather not operate retrieval infrastructure yourself, Denser Chat is the hosted product built on top of Denser Retriever — so every chatbot you create inherits the same hybrid RAG pipeline (BM25 + dense vectors + ML reranking) described above. You build a chatbot with no code by pasting a website URL or uploading documents, and Denser Chat handles chunking, indexing, hybrid retrieval, and answer generation. Once the chatbot is live, you can call it from your own application through the Denser API to run hybrid-RAG queries programmatically.
For developers building custom pipelines, our guides on building a RAG knowledge base and using Denser Retriever with LangChain walk through integration step by step.
Get Started#
Ready to add hybrid search to your RAG pipeline? Pick the path that fits you:
-
Self-host the open-source engine. Denser Retriever is an open-source project that ships the full hybrid pipeline — dual retrieval (BM25 + dense), learned fusion, and ML reranking. Clone the repo, point it at your corpus, and benchmark on your own query set for production-grade hybrid retrieval without building the infrastructure from scratch.
-
Upgrade an existing dense-only RAG system. Add a BM25 index alongside your vector store (Elasticsearch, OpenSearch, or your vector database's built-in sparse search). Fuse the two result lists with RRF at k = 60. Measure the improvement. This is the fastest single upgrade you can make to retrieval quality.
-
Use hybrid RAG without writing retrieval code — try Denser Chat. Denser Chat is the no-code product backed by Denser Retriever, so the full hybrid pipeline (BM25 + dense vectors + ML reranking) is built in. Stand up a chatbot in minutes by pasting a website URL or uploading documents, then call it from your own application through the Denser API to run hybrid-RAG queries programmatically.
-
If you are evaluating RAG approaches: Read our RAG vs Fine-Tuning decision guide to understand where hybrid retrieval fits in the broader architecture, and our guide to semantic search implementation for the technical details.
Looking for an end-to-end AI chatbot solution with hybrid retrieval built in? Try Denser Chat — built on the same open-source retrieval engine that powers enterprise RAG deployments — or explore Denser's AI chatbot features.
FAQs#
What is hybrid search in RAG?#
Hybrid search combines sparse keyword retrieval (BM25) with dense vector search in a RAG pipeline. BM25 matches exact terms (product codes, names, identifiers) while dense vector search matches semantic meaning (paraphrases, concepts). The two result lists are fused — typically using Reciprocal Rank Fusion (RRF) — into a single ranking that captures both exact-match and semantic relevance.
Is hybrid search better than vector search alone?#
In most production RAG systems, yes. Benchmarks show that hybrid search consistently outperforms either BM25 or dense vector search alone. On the WANDS e-commerce dataset, a tuned hybrid setup achieved 7.4% higher NDCG than either method individually (Turnbull, 2025). On financial documents, hybrid + reranking reached Recall@5 of 0.816 versus 0.587 for dense-only (Strich et al., 2026). The improvement comes from each method filling the other's blind spots.
What is Reciprocal Rank Fusion (RRF)?#
RRF is a fusion algorithm introduced by Cormack, Clarke, and Buettcher at the University of Waterloo in 2009 (Cormack et al., 2009). It merges multiple ranked result lists by summing the reciprocal of each document's rank position across all lists. The formula is score(d) = Σ 1/(k + rank(d)), where k is a constant (default 60). RRF operates on ranks, not raw scores, which makes it robust to the incompatible scoring scales of BM25 and cosine similarity. It requires no tuning and is the default fusion method in Elasticsearch and Qdrant.
Should I use BM25 or dense vector search?#
Use both. BM25 excels at exact-match queries (identifiers, codes, names) and rare terms that embedding models have not seen. Dense vector search excels at semantic and paraphrase queries where no keywords overlap. Running both in parallel and fusing with RRF gives you the strengths of each with minimal additional cost.
What is the difference between hybrid search and reranking?#
Hybrid search is a first-stage retrieval strategy — it determines which documents are candidates from the full index. Reranking is a second-stage precision step — it re-scores a shortlist of candidates (typically 50–200) using a cross-encoder that sees the query and document together. They are complementary: hybrid search produces a better candidate pool, and reranking produces a better final ordering. The standard production pipeline is: hybrid retrieval → RRF fusion → cross-encoder reranking → top-k to the LLM.
How much latency does hybrid search add?#
Running BM25 and dense retrieval in parallel adds minimal latency — typically 10–50ms over a single retrieval call, since both run concurrently. The bigger latency cost is reranking (100–300ms for a cross-encoder on 50–100 candidates). If latency is critical, use hybrid search without reranking first; add reranking only if your precision metrics justify the cost.
Can I use hybrid search with any vector database?#
Most major vector databases now support hybrid search: Qdrant (native RRF via Query API), Weaviate (hybrid search with selectable fusion type), Pinecone (alpha-weighted dense + sparse in a single index), and Elasticsearch (native RRF on Enterprise plans). The implementation differs across platforms — see the vendor comparison table above. For teams on Elasticsearch's free tier, client-side RRF using the ranx Python library is a production-viable workaround.
How does chunking affect hybrid search?#
Chunking determines what gets indexed in both the BM25 inverted index and the dense vector store. Chunks that split important terms (product names, identifiers) hurt both retrieval methods. Recursive character splitting at 256–512 tokens is the most reliable default for hybrid search — it produces coherent chunks that work well for both sparse and dense retrieval. See our RAG chunking strategies guide for a complete breakdown.
Explore More Resources#
- What Is RAG? (Retrieval-Augmented Generation Explained) — Complete guide to RAG architecture and implementation
- RAG vs Fine-Tuning: Which Approach to Choose? — Decision guide for when to retrieve vs when to train
- RAG Chunking Strategies: 8 Methods Compared — How to split documents for optimal retrieval
- Semantic Search Explained — The dense retrieval technology behind RAG
- Denser Retriever: Open-Source AI Retrieval — Production-grade hybrid retrieval infrastructure
- Elasticsearch Alternatives for AI Search — Choosing the right search infrastructure
- Pinecone Alternatives: Vector Database Comparison — Open-source and self-hosted vector databases
- Build a RAG Knowledge Base with Claude Code — Step-by-step tutorial
- Building an AI Knowledge Base — End-to-end guide for enterprise knowledge management
- AI Chatbot Solutions — Compare chatbot approaches for your business
References#
-
Turnbull, D. (2025). Hybrid Search: BM25, Vector & Reranking 2026. Digital Applied. URL: https://www.digitalapplied.com/blog/hybrid-search-bm25-vector-reranking-reference-2026 — WANDS e-commerce benchmark NDCG scores (BM25 0.6983, dense 0.6953, RRF 0.7068, RRF + field boosting 0.7497).
-
Strich, V., et al. (2026). From BM25 to Corrective RAG: Benchmarking Retrieval Strategies for Text-and-Table Documents. arXiv:2604.01733 (accepted at EACL 2026). URL: https://arxiv.org/html/2604.01733v1 — T2-RAGBench financial document benchmark (23,088 queries, 7,318 documents). Recall@5, MRR@3, and nDCG@10 for dense, BM25, hybrid RRF, and hybrid + Cohere Rerank.
-
Cormack, G. V., Clarke, C. L. A., & Buettcher, S. (2009). Reciprocal Rank Fusion outperforms Condorcet and individual Rank Learning Methods. SIGIR 2009. URL: https://plg.uwaterloo.ca/~gvcormac/cormacksigir09-rrf.pdf — Original RRF algorithm and the k=60 default.
-
Denser AI (2024). Denser Retriever: A Cutting-Edge AI Retriever for RAG. URL: https://denser.ai/blog/denser-retriever/ — MTEB retrieval benchmark results (NDCG@10 56.47 for hybrid XGBoost model vs 54.24 for vector-only baseline).
-
Voyage AI (2025). Introducing Rerank 2.5. URL: https://blog.voyageai.com/2025/08/11/rerank-2-5 — Vendor-stated benchmark: +7.94% accuracy over Cohere Rerank v3.5 on 93 datasets.