Denser Retriever: A Cutting-Edge AI Retriever for RAG

Introduction#

Retrieval-Augmented Generation (RAG) is an effective approach that merges retrieval-based models with generative models to improve the quality and relevance of generated content. The essence of RAG lies in utilizing a vast corpus of documents or a knowledge base to fetch pertinent information. Various tools support RAG, including Langchain and LlamaIndex.
AI Retriever is fundamental to the RAG framework, ensuring an accurate and seamless experience in AI applications. Retrievers are broadly classified into two types: keyword search and vector search. Keyword search relies on keyword matching, while vector search focuses on semantic similarity. Popular tools include Elasticsearch for keyword search and Milvus, Chroma, and Pinecone for vector search.
In the era of large language models, professionals across diverse fields, from engineers and scientists to marketers, are keen on developing RAG AI application prototypes. Tools like Langchain are instrumental in this process. For instance, users can swiftly build a RAG application for legal document analysis using Langchain and Chroma.
Denser Retriever stands out for rapid prototyping. Users can quickly install Denser Retriever and its required tools via a simple Docker Compose command. Denser Retriever doesn't just stop there; it also offers a self-host solution, enabling the deployment of enterprise-grade production solutions.
Furthermore, Denser Retriever provides comprehensive retrieval benchmarks on the MTEB retrieval dataset to ensure the highest accuracy in deployment. Users benefit not only from the ease of use of Denser Retriever but also from its state-of-the-art accuracy. Ready to get started? Try Denser Retriever.
Features#
The initial release of Denser Retriever provides the following features.
- Supporting heterogeneous retrievers such as keyword search, vector search, and ML model reranking
- Leveraging xgboost ML technique to effectively combine heterogeneous retrievers
- State-of-the-art accuracy on MTEB Retrieval benchmarking
- Demonstrating how to use Denser retriever to power an end-to-end applications such as chatbot and semantic search
Why Denser Retriever?#
- Open Source Commitment: Denser Retriever is open source, providing transparency and the opportunity for continuous community-driven enhancements.
- Production-Ready: It is designed to be ready for deployment in production environments, ensuring reliability and stability in real-world applications.
- State-of-the-art Accuracy: Denser Retriever delivers state-of-the-art accuracy, enhancing the quality of your AI applications.
- Scalability: Whether you are handling growing data needs or expanding user demands, Denser Retriever scales seamlessly to meet your requirements.
- Flexibility: The tool is adaptable to a wide range of applications and can be tailored to specific needs, making it a versatile choice for diverse industries.
In this blog, we show how to install Denser Retriever, build a retriever index from a text document or a website page, and query on such an index. Due to the space limit, we do not cover more advanced topics such as training Denser retrievers using custom datasets, evaluating on MTEB benchmark datasets and creating end to end AI applications such as chatbots. Interested users refer to the following resources for these advanced topics.
- Denser Retriever documentation
- Denser Retriever repo
Setup#
Install Denser Retriever#
We use Poetry to install and manage Denser Retriever package. We install Denser Retriever with the following command under repo root directory.
git clone https://github.com/denser-org/denser-retriever
cd denser-retriever
make installMore details can be found the DEVELOPMENT doc.
This setup is not suitable for production use as the data is not persistent and environment variables are not kept secret.
Install Elasticsearch and Milvus#
Elasticsearch and Milvus are required to run the Denser Retriever. They support the keyword search and vector search respectively. We follow the following instructions to install Elasticsearch and Milvus on a local machine (for example, your laptop).
Requirements: docker and docker compose, both are included in Docker Desktop for Mac or Windows users.
- Download docker-compose.dev.yml and save it as docker-compose.yml manually, or with the following command.
wget https://raw.githubusercontent.com/denser-org/denser-retriever/main/docker-compose.dev.yml \
-O docker-compose.yml- Start the services with the following command.
docker compose up -d
- Optionally, we can run the following command to verify that the Milvus is correctly installed.
poetry run python -m pytest tests/test_retriever_milvus.py
The Elasticsearch and Milvus services will be started in the background. You can check the status of the services with the following command.
docker compose psIndex and Query Use Case#
In the index and query use case, users provide a collection of documents, such as text files or webpages, to build a retriever. Users can then query this retriever to obtain relevant results from the provided documents. The code for this use case is available at index_and_query_from_docs.py. To run this example, navigate to the denser-retriever repository and execute the following command:
poetry run python experiments/index_and_query_from_docs.py
If the run is successful, we would expect to see something similar to the following.
2024-05-27 12:00:55 INFO: ES ingesting passages.jsonl record 96
2024-05-27 12:00:55 INFO: Done building ES index
2024-05-27 12:00:55 INFO: Remove existing Milvus index state_of_the_union
2024-05-27 12:00:59 INFO: Milvus vector DB ingesting passages.jsonl record 96
2024-05-27 12:01:03 INFO: Done building Vector DB index
[{'source': 'tests/test_data/state_of_the_union.txt',
'text': 'One of the most serious constitutional responsibilities...',
'title': '', 'pid': 73,
'score': -1.6985594034194946}]In the following section, we will explain the underlying processes and mechanisms involved.
Overview#
The following diagram illustrates a denser retriever, which consists of three components:
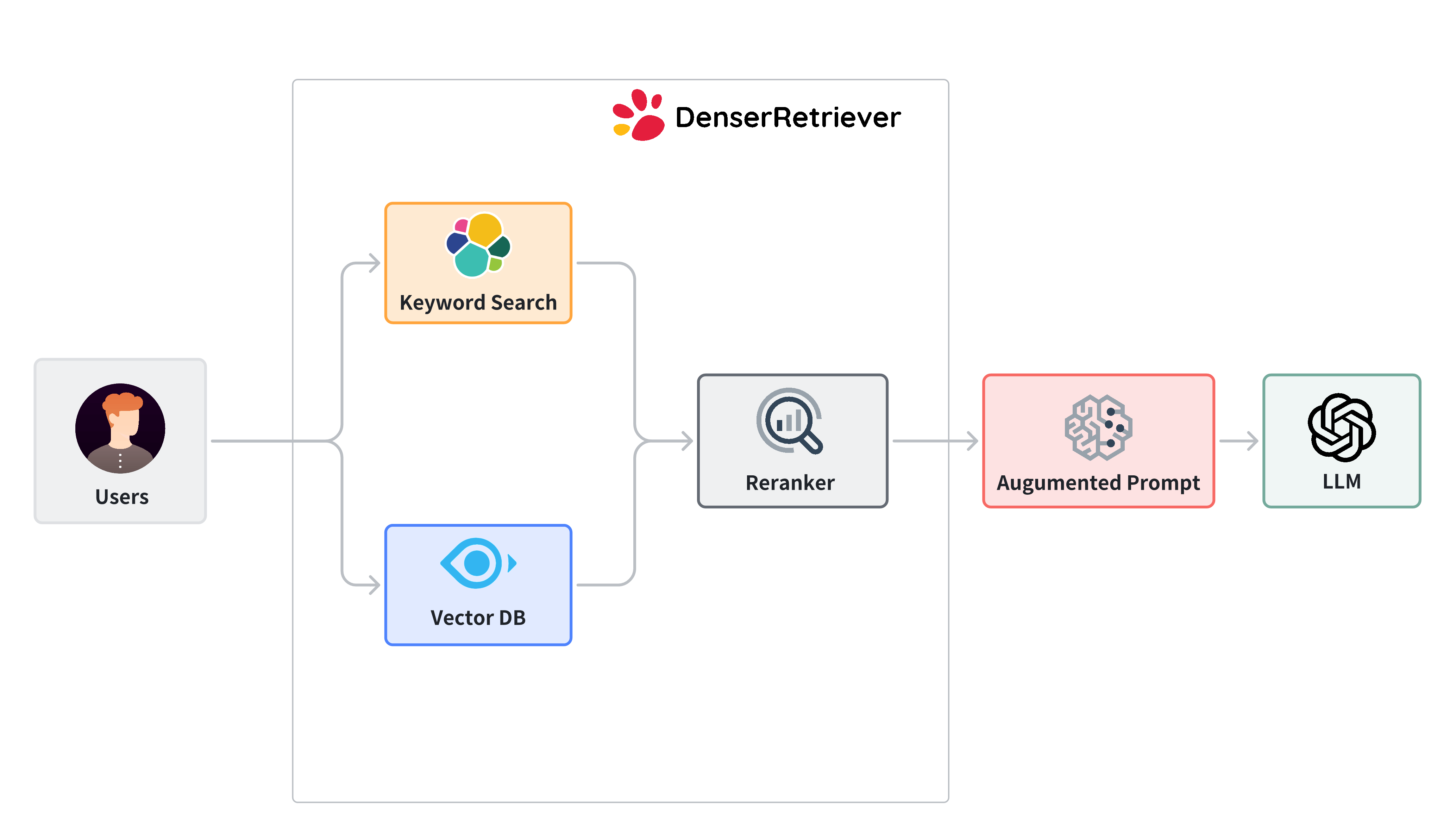
- Keyword search relies on traditional search techniques that use exact keyword matching. We use Elasticsearch in denser retriever.
- Vector search uses neural network models to encode both the query and the documents into dense vector representations in a high-dimensional space. We use Milvus and snowflake-arctic-embed-m model, which achieves state-of-the-art performance on the MTEB/BEIR leaderboard for each of their size variants.
- A ML cross-encoder re-ranker can be utilized to further boost accuracy over these two retriever approaches above. We use cross-encoder/ms-marco-MiniLM-L-6-v2, which has a good balance between accuracy and inference latency.
Prepare the config file#
We config the above three components in the following yaml file (available at repo). Most of the parameters are self-explanatory. The sections of keyword, vector, rerank config the Elasticsearch, Milvus, and reranker respectively.
We uses combine: model to combine Elasticsearch, Milvus and reranker via a xgboost model experiments/models/msmarco_xgb_es+vs+rr_n.json, which was trained using mteb msmarco dataset (see the training recipe on how to train such a model). Besides the model combination, we can also use linear or rank to combine Elasticsearch, Milvus and reranker. The experiments on MTEB datasets suggest that the model combination can lead to significantly higher accuracy than the linear or rank methods.
Some parameters, for example, es_ingest_passage_bs, are only used in training a xgboost model (i.e. not needed in query stage).
version: "0.1"
# linear, rank or model
combine: model
keyword_weight: 0.5
vector_weight: 0.5
rerank_weight: 0.5
model: ./experiments/models/msmarco_xgb_es+vs+rr_n.json
model_features: es+vs+rr_n
keyword:
es_user: elastic
es_passwd: YOUR_ES_PASSWORD
es_host: http://localhost:9200
es_ingest_passage_bs: 5000
topk: 100
vector:
milvus_host: localhost
milvus_port: 19530
milvus_user: root
milvus_passwd: Milvus
emb_model: Snowflake/snowflake-arctic-embed-m
emb_dims: 768
one_model: false
vector_ingest_passage_bs: 2000
topk: 100
rerank:
rerank_model: cross-encoder/ms-marco-MiniLM-L-6-v2
rerank_bs: 100
topk: 100
output_prefix: ./denser_output_retriever/
max_doc_size: 0
max_query_size: 10000Generate passages#
We now describe how to build a retriever from a given text file: the state_of_the_union.txt. The following code shows how to read the text file, split the file to text chunks and save them to a jsonl file passages.jsonl.
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from denser_retriever.utils import save_HF_docs_as_denser_passages
from denser_retriever.retriever_general import RetrieverGeneral
# Generate text chunks
documents = TextLoader("tests/test_data/state_of_the_union.txt").load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
texts = text_splitter.split_documents(documents)
passage_file = "passages.jsonl"
save_HF_docs_as_denser_passages(texts, passage_file, 0)Each line in passages.jsonl is a passage, which contains fields of source, title, text and pid (passage id).
{
"source": "tests/test_data/state_of_the_union.txt",
"title": "",
"text": "Madam Speaker, Madam Vice President, our First Lady and Second Gentleman...",
"pid": 0
}Build a Denser retriever#
We can build a Denser retriever with the given passages.jsonl and experiments/config_local.yaml config file.
# Build denser index
retriever_denser = RetrieverGeneral("state_of_the_union", "experiments/config_local.yaml")
retriever_denser.ingest(passage_file)Query a Denser retriever#
We can simply use the following code to query a retriever to obtain relevant passages.
# Query
query = "What did the president say about Ketanji Brown Jackson"
passages, docs = retriever_denser.retrieve(query, {})
print(passages)Each returned passage receives a confidence score to indicate how relevant it is to the given query. We get something similar to the following.
[{'source': 'tests/test_data/state_of_the_union.txt',
'text': 'One of the most serious constitutional...',
'title': '', 'pid': 73,
'score': -1.6985594034194946}]Put everything together#
We put all code together as follows. The code is also available at repo.
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from denser_retriever.utils import save_HF_docs_as_denser_passages
from denser_retriever.retriever_general import RetrieverGeneral
# Generate text chunks
documents = TextLoader("tests/test_data/state_of_the_union.txt").load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
texts = text_splitter.split_documents(documents)
passage_file = "passages.jsonl"
save_HF_docs_as_denser_passages(texts, passage_file, 0)
# Build denser index
retriever_denser = RetrieverGeneral("state_of_the_union", "experiments/config_local.yaml")
retriever_denser.ingest(passage_file)
# Query
query = "What did the president say about Ketanji Brown Jackson"
passages, docs = retriever_denser.retrieve(query, {})
print(passages)Build and query a retriever from a webpage#
Building a retriever from a webpage is similar to the above, except for the passage corpus generation. The index_and_query_from_webpage.py source code can be found at here.
To run this use case, go to denser-retriever repo and run:
poetry run python experiments/index_and_query_from_webpage.py
If successful, we expect to see somthing similar to the following.
2024-05-27 12:10:47 INFO: ES ingesting passages.jsonl record 66
2024-05-27 12:10:47 INFO: Done building ES index
2024-05-27 12:10:52 INFO: Milvus vector DB ingesting passages.jsonl record 66
2024-05-27 12:10:56 INFO: Done building Vector DB index
[{'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/',
'text': 'Fig. 1. Overview of a LLM-powered autonomous agent system...',
'title': '',
'pid': 2,
'score': -1.6985594034194946}]Further reading#
Due to the space limit, we did not include the following topics in this blog.
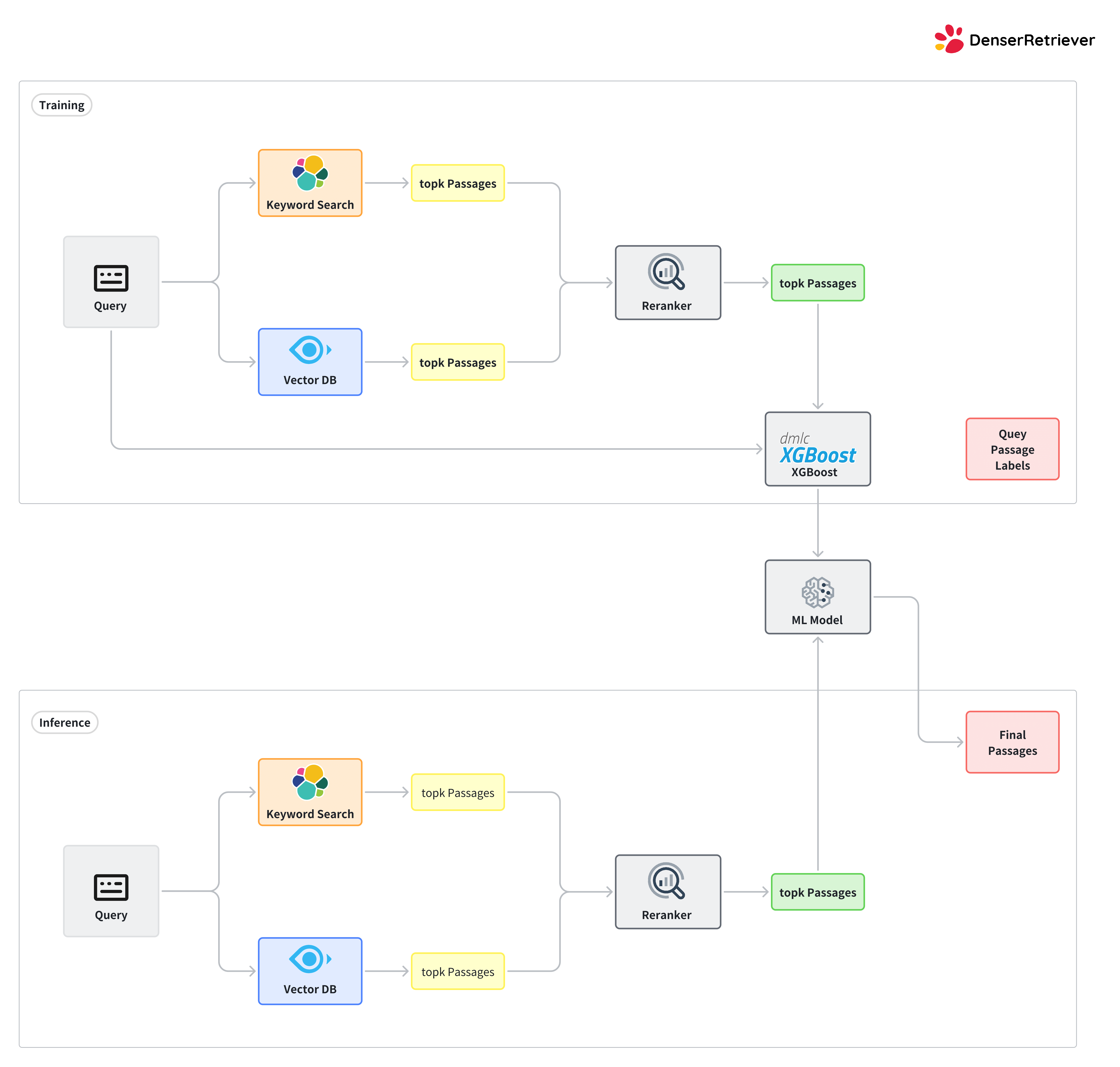
- Training Denser Retriever using customer datasets. Users provide a training dataset to train a xgboost model which governs on how to combine keyword search, vector search and reranking. The training and test workflows are illustrated in the following.
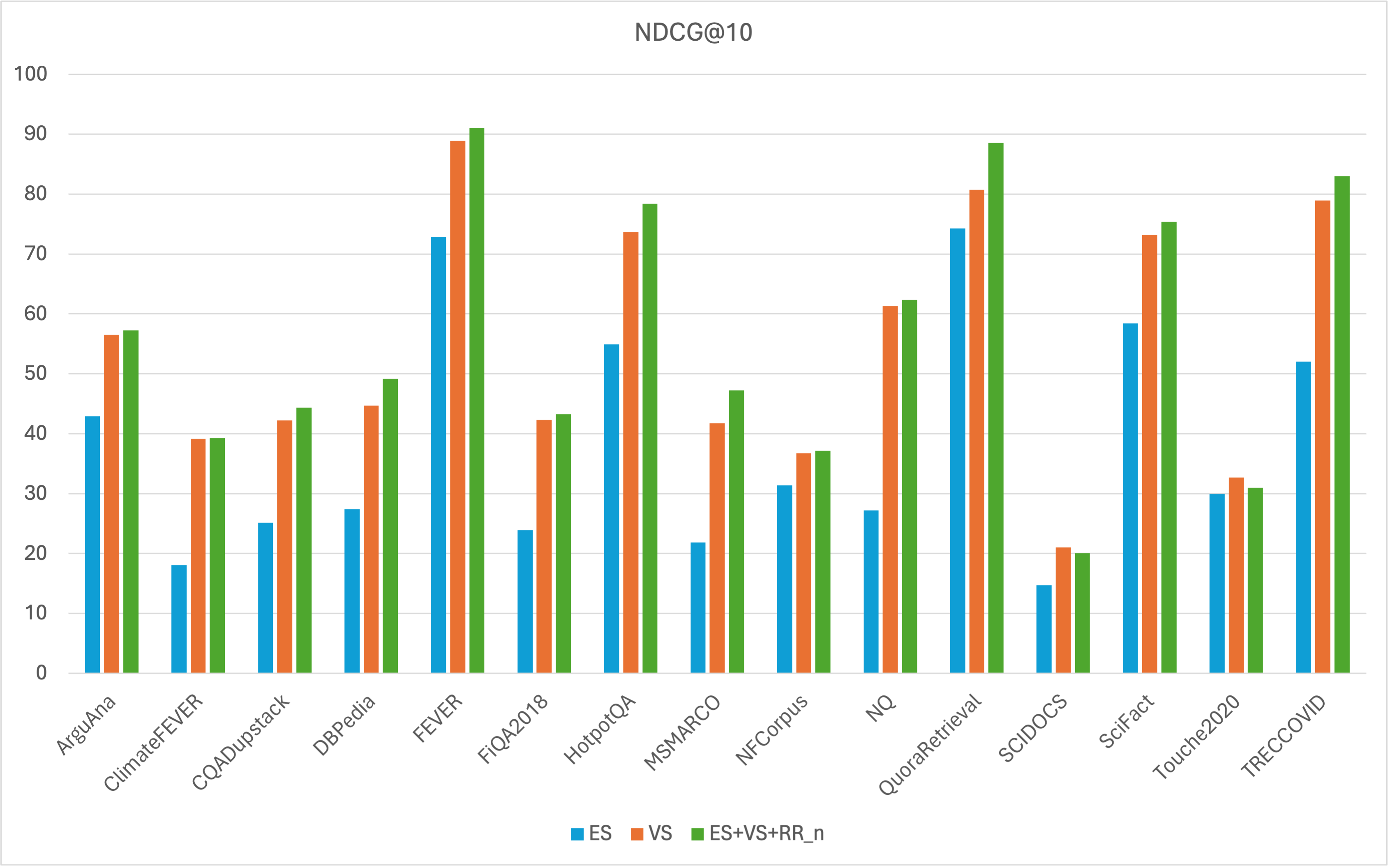
- Evaluating Denser Retriever on MTEB datasets. The combination of keyword search, vector search and a reranker via xgboost models can further improve the vector search baseline. For instance, our best xgboost model achieves the NDCG@10 score of 56.47, surpassing the vector search baseline (NDCG@10 of 54.24) by an absolute increase of 2.23 and a relative improvement of 4.11%, when tested on all MTEB datasets.
- End to end search and chat applications. We can easily build end to end chatbots with Denser Retriever.

- Filters. The above index and query use case assumes the search items contain unstructured text only. This assumption may not hold as datasets may contain numerical, categorical and date attributes. Filters can be used to set constraints for these attributes.
Interested users can refer to the following resources for the aforementioned topics.
- Denser Retriever documentation
- Denser Retriever repo
Get in Touch#
We are excited to hear your feedback and suggestions. Please feel free to reach out to us at