RAG vs Fine-Tuning: Which Approach to Choose? (2026 Decision Guide)

TL;DR: Use RAG when your knowledge changes frequently or you need source citations. Use fine-tuning when you need the model to adopt a specific style, format, or domain behavior. Use both when accuracy AND style matter.
| Criteria | RAG | Fine-Tuning |
|---|---|---|
| Knowledge freshness | Real-time — query live data | Static — frozen at training time |
| Source citations | ✅ Built-in traceability | ❌ No source tracking |
| Style/format control | Limited — relies on prompting | ✅ Deeply embedded in weights |
| Cost to update knowledge | Low — update the vector store | High — retrain the model |
| Inference latency | Higher (retrieval + generation) | Lower (generation only) |
| Infrastructure | Vector DB + embedding pipeline | GPU training + model hosting |
| Data requirements | Documents, web pages, databases | Curated input–output pairs |
| Best for | Frequently changing knowledge, factuality | Consistent style, domain reasoning |
Read on for a detailed breakdown, cost analysis, and a step-by-step decision framework that helps you choose the right approach — or combine both.
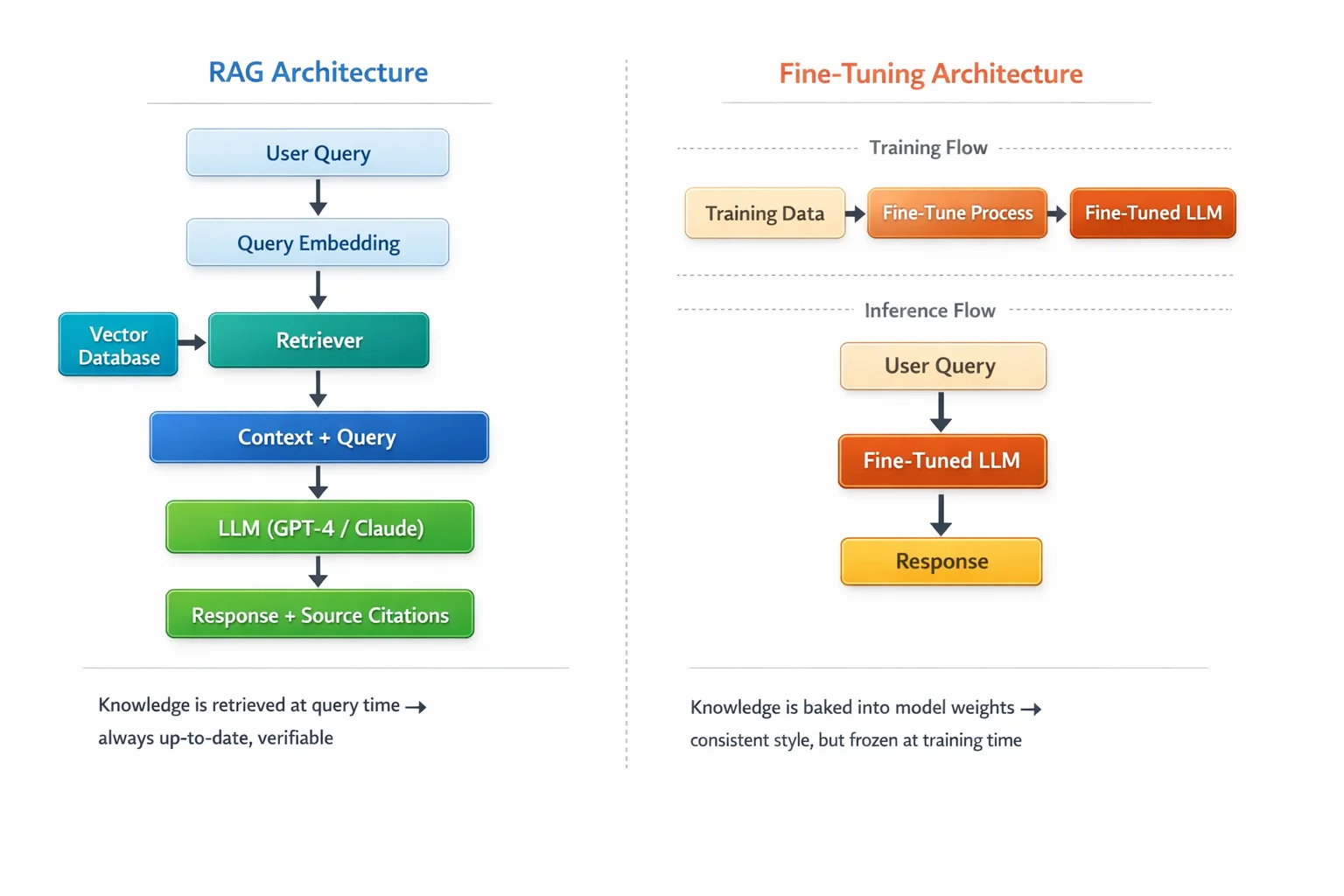
RAG retrieves knowledge at query time; fine-tuning bakes knowledge into model weights during training. The diagram above shows why this matters: RAG flows through a retrieval step that pulls from your vector database every time, while fine-tuning modifies the LLM itself so it responds from internalized patterns.
What Is RAG?#
Retrieval-Augmented Generation (RAG) connects a large language model to an external knowledge base at inference time. Instead of relying solely on what the model learned during pre-training, RAG first retrieves relevant documents from a vector store, then feeds those documents as context to the LLM so it can generate a grounded, accurate response.
Think of it as open-book exam: the model can look up the answer instead of guessing from memory. This means you can update what the model "knows" by simply adding or updating documents in your knowledge base — no retraining required.
For a deep dive into how RAG works, its architecture, and implementation details, read our complete guide: What Is RAG? (Retrieval-Augmented Generation Explained).
What Is Fine-Tuning?#
Fine-tuning takes a pre-trained LLM and trains it further on a curated dataset of domain-specific examples — typically input–output pairs that demonstrate the behavior you want. This process adjusts the model's weights so it internalizes patterns, styles, and domain knowledge directly.
Think of it as sending a generalist to specialized training: the model becomes an expert in your specific domain, producing responses that consistently match your desired format, tone, and reasoning style — without needing extra prompting or retrieved context at inference time.
Unlike RAG, fine-tuning doesn't add new factual knowledge on the fly. The model's knowledge is frozen at the point of training. But what it gains is behavioral consistency — the model "becomes" the role you need it to play, whether that's a legal contract drafter, a medical report summarizer, or a brand-voiced customer support agent.
RAG vs Fine-Tuning: Side-by-Side Comparison#
Let's go deeper than the quick comparison above. Here's a detailed breakdown across every dimension that matters for production systems:
| Dimension | RAG | Fine-Tuning |
|---|---|---|
| How knowledge is stored | External vector database | Inside model weights |
| Knowledge update frequency | On-demand — add/update/delete documents anytime | Only by retraining on new data |
| Factual accuracy | High (grounded in retrieved sources) | Moderate (depends on training data recency) |
| Hallucination risk | Lower — retrieval anchors responses | Higher — no external grounding mechanism |
| Source attribution | ✅ Can cite exact passages | ❌ Cannot trace to sources |
| Style & tone consistency | Requires careful prompting | ✅ Baked into model behavior |
| Complex reasoning patterns | Limited — context window constraints | ✅ Can internalize domain logic |
| Prompt length at inference | Long (retrieved context + query) | Short (query only) |
| Inference latency | Higher (embedding query → search → LLM call) | Lower (single LLM call) |
| Infrastructure complexity | Vector DB, embedding model, retriever pipeline | Training GPU + model serving endpoint |
| Scalability of knowledge | Millions of documents — limited by vector DB | Limited by training data size & model capacity |
| Cost to add new knowledge | Low — index new documents | High — curate data + retrain |
| Cost per query | Higher (retrieval + generation) | Lower (generation only) |
| Data privacy | Documents stay in your DB; not in model weights | Training data is absorbed into model weights |
| Catastrophic forgetting risk | Not applicable | ✅ Real risk when fine-tuning on narrow data |
| Technical expertise needed | Moderate (vector search, chunking, embeddings) | High (ML engineering, data curation, training loops) |
| When it shines | Dynamic knowledge, auditability, large doc corpora | Style lock-in, domain reasoning, low-latency inference |
When to Use RAG#
RAG is the right choice when your primary challenge is getting the right information to the model — not teaching the model a new behavior. Here are specific scenarios where RAG outperforms fine-tuning:
1. Your Knowledge Base Changes Frequently#
If your content updates daily, weekly, or even monthly — product catalogs, policy documents, pricing sheets, news archives — RAG lets you update the vector store in minutes without retraining. Fine-tuning would require curating new training examples and running an expensive training loop every time.
Example: An e-commerce chatbot that answers questions about current inventory, pricing, and promotions. Product data changes constantly; RAG keeps the bot current.
2. You Need Source Citations and Auditability#
In regulated industries — legal, healthcare, finance — you can't just present an answer. You need to show where it came from. RAG naturally provides citations because every response is grounded in retrieved documents that you can trace back.
Example: A legal research assistant that cites specific case law and statutes. Fine-tuning can't tell you which training example shaped its output.
3. You Have a Large, Diverse Document Collection#
When your knowledge spans thousands or millions of documents — internal wikis, support tickets, research papers — it's impractical to compress all that into training data. RAG searches the full corpus at query time, so no knowledge is left behind.
Example: An enterprise AI knowledge base that spans engineering docs, HR policies, and sales playbooks across 50,000+ pages.
4. You Need Cost-Effective Knowledge Updates#
Adding a new document to a RAG system costs pennies — embed it, index it, done. Retraining a fine-tuned model on new data costs hundreds or thousands of dollars in GPU compute, plus the engineering time to prepare the data.
Example: A customer support bot that needs to learn about a newly launched feature. With RAG, you upload the release notes; with fine-tuning, you'd need to generate Q&A pairs and retrain.
5. Data Privacy Requires Keeping Documents Separate#
If your compliance policy requires that raw documents never leave your infrastructure or get absorbed into a model's weights, RAG is the safer approach. Documents stay in your vector database; only relevant chunks are retrieved at query time.
Example: A healthcare system where patient records and clinical guidelines must remain in a controlled database — not baked into a model that could be shared or deployed elsewhere.
6. You're Building a Proof of Concept Quickly#
RAG systems can be stood up in hours: chunk your documents, embed them, point a retriever at the vector store, and connect to an LLM. Fine-tuning requires data curation, training runs, evaluation, and iteration — a process that takes days to weeks.
Example: A team that needs a working prototype of a semantic search and Q&A system by next week.
When to Use Fine-Tuning#
Fine-tuning wins when your challenge is teaching the model how to behave, not what to know. Here are the scenarios where fine-tuning delivers better results:
1. You Need Consistent Style, Tone, and Formatting#
If every response must match a specific brand voice, adhere to a rigid format, or follow domain-specific conventions, fine-tuning embeds those patterns directly into the model. No amount of prompting in a RAG system matches the consistency of a model that has been trained to produce output in exactly your style.
Example: A financial reporting assistant that always outputs in a specific Markdown table format with consistent terminology. Prompting can get close, but fine-tuning nails it every time.
2. You Want to Reduce Prompt Length and Cost#
RAG systems stuff the context window with retrieved documents, which increases token count and cost per query. Fine-tuned models don't need retrieved context — they've internalized the patterns — so inference is cheaper and faster.
Example: A high-traffic customer support bot handling 100K queries/day. Reducing each prompt by 2,000 tokens saves thousands of dollars monthly.
3. Your Domain Requires Specialized Reasoning#
Some domains have reasoning patterns that are hard to convey through retrieved context alone — medical differential diagnosis, legal argumentation, engineering design logic. Fine-tuning can teach the model the process of reasoning, not just the facts.
Example: A medical assistant trained to follow a specific diagnostic workflow — not just retrieve medical literature, but reason through symptoms to suggest differential diagnoses.
4. Low Latency Is Critical#
RAG adds latency: embed the query → search the vector store → construct the prompt → call the LLM. If your application needs sub-second responses (real-time voice assistants, interactive UIs, high-frequency trading summaries), fine-tuning's single-pass inference is faster.
Example: A voice-based AI assistant that must respond within 500ms. The retrieval step alone in RAG can take 200-400ms.
5. You Need the Model to Follow Complex, Multi-Step Instructions#
When the task involves nuanced, multi-step procedures that must be followed exactly — and where deviation is costly — fine-tuning creates a model that reliably follows the procedure without lengthy system prompts that eat into your context window.
Example: An insurance claims processor that must follow a 15-step adjudication workflow. Fine-tuning ensures no step is skipped; prompting relies on the model correctly parsing and following a long instruction block.
6. You're Working in a Narrow, Stable Domain#
If your domain knowledge changes rarely and the corpus is small enough to capture in training data, fine-tuning can internalize that knowledge effectively. You get the benefit of domain expertise without the infrastructure overhead of a retrieval system.
Example: A bot that answers questions about a specific, stable API. The API documentation rarely changes, and the number of endpoints is manageable.
RAG + Fine-Tuning: The Hybrid Approach#
Here's what most production systems discover: you need both. RAG alone gives you accurate, cited answers but can't control style. Fine-tuning alone gives you consistent behavior but serves stale facts. The hybrid approach combines the strengths of each.
How the Hybrid Approach Works#
- Fine-tune the base model on your domain's style, format, and reasoning patterns. This gives you a model that speaks your language.
- Deploy RAG on top of the fine-tuned model. The retrieval system provides fresh, grounded context at query time.
- The fine-tuned model processes the retrieved context with domain-appropriate reasoning, producing responses that are both accurate AND stylistically consistent.
When to Use the Hybrid Approach#
- You need both factuality and style. Legal, medical, and financial applications demand accurate citations and domain-appropriate formatting and reasoning.
- Your knowledge changes AND your format matters. Customer support that must cite current policies and respond in brand voice.
- You're operating at scale. High-volume systems where both accuracy and consistency are SLA requirements.
Real-World Hybrid Architecture#
A typical hybrid system looks like this:
- Step 1: A fine-tuned LLM (trained on your domain's Q&A patterns, output formats, and reasoning workflows)
- Step 2: A RAG retrieval layer (vector database of current documents, powered by semantic search)
- Step 3: Query-time flow: User query → retrieve relevant context → feed context + query to fine-tuned LLM → response with citations in your format
This is the architecture that most enterprise AI deployments converge toward. Start with RAG for speed, add fine-tuning for consistency, and you end up with a system that does both well.
Cost Comparison: RAG vs Fine-Tuning#
Cost is often the deciding factor. Let's break it down with real numbers for a mid-size deployment.
RAG Costs#
| Cost Component | Typical Monthly Cost | Notes |
|---|---|---|
| Vector database hosting | $50–$300 | Depends on corpus size (e.g., Pinecone, Weaviate, self-hosted) |
| Embedding API calls | $20–$150 | For indexing + query embeddings (OpenAI text-embedding-3-small) |
| LLM inference (generation) | $100–$2,000 | Depends on query volume and context length |
| Document ingestion pipeline | $50–$200 | Chunking, embedding, indexing pipeline |
| Total monthly | $220–$2,650 | Scales linearly with query volume |
Fine-Tuning Costs#
| Cost Component | Typical One-Time Cost | Notes |
|---|---|---|
| Training data preparation | $2,000–$10,000 | Manual curation, quality review, formatting |
| GPU training (LoRA/QLoRA) | $50–$500 | 1–8 A100 GPUs for 2–12 hours |
| GPU training (full fine-tune) | $500–$5,000 | 8+ A100 GPUs for longer runs |
| Evaluation & iteration | $500–$3,000 | Multiple training runs, benchmarking |
| Model hosting (fine-tuned) | $100–$800/mo | Dedicated endpoint for fine-tuned model |
| Retraining (knowledge updates) | $500–$5,000 per cycle | Every time you need to update knowledge |
| Total initial + first year | $4,150–$27,600 | Higher upfront, lower per-query cost |
Key Cost Takeaways#
- RAG is cheaper to start and cheaper to maintain if your knowledge changes frequently. You avoid the expensive retraining cycles.
- Fine-tuning is cheaper per query at high volume, but the upfront and maintenance costs are significant.
- The hybrid approach costs more in infrastructure (you need both a vector DB and a fine-tuned model endpoint) but delivers the best ROI when both accuracy and consistency are business requirements.
- 2026 cost shift: LoRA and QLoRA have dramatically reduced fine-tuning costs — what used to require $5,000 in GPU compute now costs $50–$500. This makes fine-tuning accessible to teams that previously couldn't afford it.
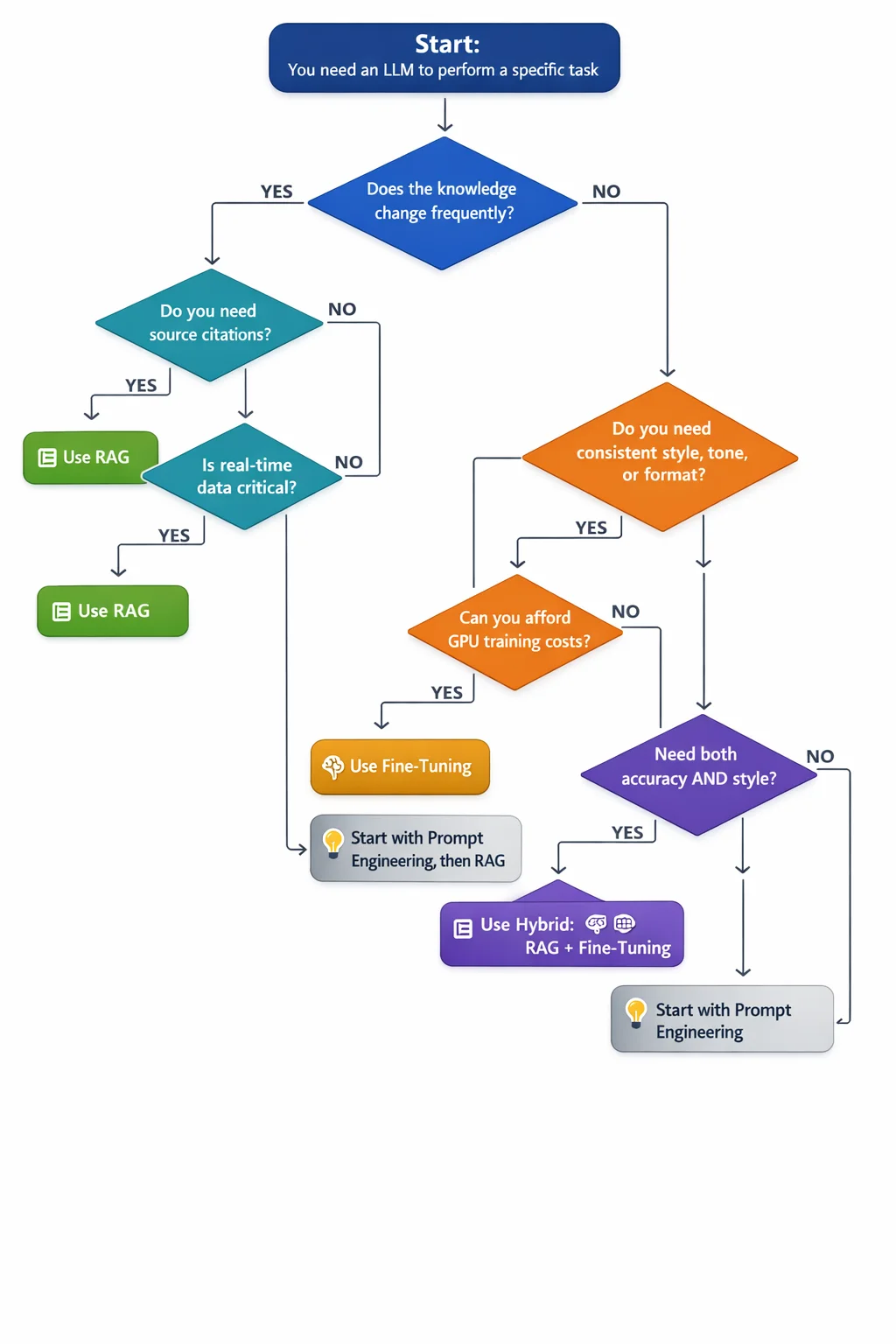
Follow the flow from top to bottom. Start with whether your knowledge changes frequently — if yes, RAG is almost always the right starting point. If not, the decision hinges on whether you need consistent style and format, or whether simpler prompt engineering suffices.
The Decision Framework#
Stop guessing. Use this framework to make the right call for your project.
Step 1: Ask the Knowledge Question#
Does your application need access to frequently changing or new information?
- Yes → You need RAG (or RAG + fine-tuning). Fine-tuning alone can't keep up with changing knowledge.
- No → Move to Step 2.
Step 2: Ask the Style Question#
Does your application require the model to produce output in a specific style, format, or reasoning pattern — consistently, every time?
- Yes → You need fine-tuning (or RAG + fine-tuning). Prompting alone won't deliver the consistency you need.
- No → Move to Step 3.
Step 3: Ask the Simplicity Question#
Can prompt engineering solve your problem?
- Yes → Start with prompt engineering. It's the cheapest, fastest approach. Graduate to RAG or fine-tuning only when prompting fails.
- No → You likely need RAG for the knowledge dimension, fine-tuning for the behavior dimension, or both.
The Decision Flow#
Follow this path:
- Frequently changing knowledge + source citations needed → RAG
- Frequently changing knowledge + low latency critical → Fine-tuning + RAG (fine-tune for speed, RAG for freshness)
- Stable knowledge + consistent style/format → Fine-tuning
- Stable knowledge + no style requirements → Prompt engineering (start simple)
- Changing knowledge + consistent style + factuality → RAG + Fine-tuning (the hybrid)
Quick Scenarios#
| Your Scenario | Recommendation |
|---|---|
| Customer support bot with product docs that update weekly | RAG — knowledge changes, citations help agents verify answers |
| Medical report formatter that must follow strict templates | Fine-tuning — style/format is the core requirement |
| Legal research assistant citing current case law in firm's format | RAG + Fine-tuning — need both citations and format |
| Internal wiki Q&A for a 10,000-page knowledge base | RAG — large, changing corpus, need traceability |
| Code review bot following your team's specific review patterns | Fine-tuning — stable domain, behavioral consistency matters |
| Financial analyst assistant citing real-time market data in structured reports | RAG + Fine-tuning — fresh data + strict output format |
What's New in 2026: LoRA, Long-Context Models, and Agentic RAG#
The RAG vs fine-tuning landscape is evolving fast. Here are the developments reshaping the decision in 2026:
LoRA and QLoRA: Fine-Tuning for Everyone#
Low-Rank Adaptation (LoRA) and Quantized LoRA (QLoRA) have democratized fine-tuning. Instead of updating all model parameters, LoRA trains small adapter layers — reducing GPU requirements by 10–50x. What used to require 8 A100 GPUs for 12 hours now runs on a single GPU in 1–2 hours.
Impact on the decision: Fine-tuning is no longer prohibitively expensive. If cost was your reason for avoiding fine-tuning, reconsider — LoRA makes it viable for small teams.
Long-Context Models: Reducing (But Not Eliminating) RAG Need#
Models with 128K–1M token context windows can hold entire document collections in a single prompt. Does this make RAG obsolete? Not quite:
- Cost: Stuffing 100K tokens into every query is expensive. RAG retrieves only what's relevant.
- Quality: Models still reason better over focused context than over massive dumps. Retrieval improves signal-to-noise ratio.
- Scale: No context window holds a million-document corpus. RAG still wins for large-scale knowledge.
Impact on the decision: Long-context models reduce RAG's necessity for small document collections. For anything over a few hundred pages, RAG remains essential.
Agentic RAG: Beyond Simple Retrieval#
Agentic RAG combines retrieval with tool use, multi-step reasoning, and autonomous decision-making. Instead of a single retrieve-then-generate loop, an agentic RAG system can:
- Query multiple knowledge sources in sequence
- Use tools (calculators, APIs, databases) alongside retrieval
- Self-correct when initial retrieval is insufficient
- Plan multi-step research workflows
Impact on the decision: Agentic RAG expands what RAG can handle — making it competitive for complex reasoning tasks that previously favored fine-tuning.
GraphRAG: Structured Knowledge Retrieval#
GraphRAG augments vector retrieval with knowledge graph traversal, enabling the system to reason over relationships between entities (not just semantic similarity). This is particularly powerful for domains with rich relational structure — organizational hierarchies, supply chains, biological pathways.
Impact on the decision: GraphRAG extends RAG's effectiveness into structured, relational domains where simple semantic retrieval previously fell short.
Denser Retriever: Open-Source RAG Infrastructure#
If you're building a RAG system — whether standalone or hybrid — you need robust retrieval infrastructure. Denser Retriever is an open-source AI-powered retrieval engine designed for production RAG deployments.
Why Denser Retriever for Your RAG Stack#
- Hybrid retrieval: Combines dense vector search with sparse (keyword) retrieval and Elasticsearch alternatives for best-of-both-worlds accuracy
- Source citations built-in: Every retrieved chunk includes metadata for full traceability — exactly what you need when the "RAG vs fine-tuning" decision points you toward RAG
- Production-ready: Designed for reliability at scale, not just demos
- Easy integration: Works with popular LLM providers and vector databases
- Open source: Inspect, modify, and extend to fit your exact requirements
Denser Retriever powers the retrieval layer for teams that need accurate, citation-backed responses — the core advantage of RAG over fine-tuning.
Try it live at retriever.denser.ai or explore the codebase on GitHub.
Get Started#
Ready to build? Here's your action plan based on the framework above:
-
If you chose RAG: Start by setting up your vector database, chunk your documents, and connect a retriever. Follow our step-by-step guide: Build a RAG Knowledge Base with Claude Code. Use Denser Retriever for production-grade retrieval.
-
If you chose Fine-tuning: Prepare your training dataset (high-quality input–output pairs are everything), choose a LoRA/QLoRA framework (Unsloth, Axolotl, or Hugging Face PEFT), and start with a small training run. Evaluate before scaling.
-
If you chose the Hybrid Approach: Start with RAG to get factuality right, then add fine-tuning for style consistency. This phased approach de-risks the project.
-
If you're still unsure: Start with Denser Retriever and RAG. It's the fastest path to a working system. You can always add fine-tuning later.
Looking for an end-to-end AI chatbot solution? Explore Denser's AI chatbot features — built on the same retrieval infrastructure that powers enterprise RAG deployments.
FAQs#
Is RAG better than fine-tuning?#
Neither is universally better. RAG is better when you need frequently updated knowledge and source citations. Fine-tuning is better when you need consistent style, format, and domain-specific reasoning. Most production systems benefit from combining both. See the decision framework above for your specific scenario.
When should I use RAG vs fine-tuning?#
Use RAG when your knowledge changes frequently, you need source citations, or you have a large document corpus. Use fine-tuning when you need the model to produce output in a consistent style or format, follow complex domain reasoning patterns, or achieve low-latency inference. When both matter, use the hybrid approach.
Can you combine RAG and fine-tuning?#
Yes — and most production systems eventually do. Fine-tune the model for your domain's style and reasoning patterns, then deploy RAG on top for fresh, grounded knowledge. The fine-tuned model processes retrieved context with domain-appropriate behavior, giving you both accuracy and consistency.
How much does RAG cost compared to fine-tuning?#
RAG typically costs $220–$2,650/month for a mid-size deployment (vector DB hosting, embedding API calls, LLM inference). Fine-tuning has higher upfront costs ($4,150–$27,600 for initial training + first year) but lower per-query cost at high volume. In 2026, LoRA has reduced fine-tuning costs dramatically — training runs that previously cost $5,000 now cost $50–$500.
Does fine-tuning cause catastrophic forgetting?#
Yes, catastrophic forgetting is a real risk. When you fine-tune a model on narrow domain data, it can lose general capabilities it learned during pre-training. Mitigation strategies include: using LoRA (which preserves base weights), mixing general examples into your training data, and regular evaluation on both domain-specific and general benchmarks.
Is RAG slower than fine-tuning?#
RAG has higher latency per query because it requires a retrieval step (embed query → search vector DB → construct prompt) before LLM generation. Fine-tuning skips retrieval, so inference is faster. However, RAG latency is typically 200–600ms total, which is acceptable for most applications. For sub-second voice or real-time applications, this difference matters.
What is agentic RAG?#
Agentic RAG extends traditional RAG with autonomous tool use and multi-step reasoning. Instead of a single retrieve-then-generate loop, an agentic RAG system can query multiple sources, use external tools (calculators, APIs), self-correct when retrieval is insufficient, and plan multi-step research workflows. It expands RAG's effectiveness for complex tasks.
Should I start with prompt engineering before RAG or fine-tuning?#
Always. Prompt engineering is the cheapest, fastest approach and solves many problems without additional infrastructure. Move to RAG when prompting fails to deliver accurate, up-to-date information. Move to fine-tuning when prompting fails to deliver consistent style and behavior. The progression is: prompt engineering → RAG → fine-tuning → hybrid.
Explore More Resources#
- What Is RAG? (Retrieval-Augmented Generation Explained) — Our complete guide to RAG architecture and implementation
- Build a RAG Knowledge Base with Claude Code — Step-by-step tutorial
- Denser Retriever: Open-Source AI Retrieval — Production-grade retrieval infrastructure
- Semantic Search Explained — The search technology behind RAG
- Elasticsearch Alternatives for AI Search — Choosing the right search infrastructure
- Building an AI Knowledge Base — End-to-end guide for enterprise knowledge management
- AI Chatbot Solutions — Compare chatbot approaches for your business
- Denser AI Chatbot Features — Production chatbot infrastructure