What Is RAG (Retrieval-Augmented Generation)? Complete Guide 2026

RAG Definition — RAG stands for Retrieval-Augmented Generation. It is an AI architecture that retrieves relevant content from your own data sources before generating a response, making answers grounded and verifiable instead of hallucinated. In practice, RAG pairs a large language model (LLM) with a retrieval system — typically a vector database — so the model's output is always anchored to real, citable information.
TL;DR — RAG (Retrieval-Augmented Generation) is the technique that lets LLMs "look things up" before they answer. Instead of relying solely on training data that may be outdated or incomplete, a RAG system searches your documents, pulls the most relevant passages, and feeds them into the LLM as context. The result: answers that are accurate, up-to-date, and traceable to source material. This guide covers how RAG works, its architecture, key components, evaluation metrics, common failure modes, industry use cases, and the cutting edge — agentic and multimodal RAG.
What Is RAG?#
RAG — Retrieval-Augmented Generation — is an AI framework that solves the most persistent problem with large language models: they hallucinate. An LLM trained on the public internet has broad knowledge but no access to your private data, your latest policies, or niche domain details. RAG bridges that gap by retrieving relevant documents at query time and augmenting the LLM's prompt with that retrieved content before it generates a response.
New to the concept? Start with our plain-English primer, RAG Explained, then come back here for the full pipeline, frameworks, and implementation details.
Why RAG Matters#
Before RAG, enterprises had two imperfect options for getting domain-specific answers out of LLMs:
- Prompt engineering — stuff everything into the context window. Works until the window fills up.
- Fine-tuning — retrain the model on your data. Expensive, slow, and still prone to hallucination because fine-tuning teaches style, not facts.
RAG offers a third path that is faster to deploy, cheaper to maintain, and more reliable in production. Every time a user asks a question, the system fetches the freshest relevant documents and constructs a grounded prompt. The LLM never has to rely on stale training data alone.
The concept was formalized in the 2020 paper "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks" by Lewis et al. at Meta AI, and has since become the standard architecture for production AI applications — from customer support chatbots to legal research assistants to enterprise search.
RAG Meaning in AI#
When people ask "what is RAG in AI?" or "what does RAG mean?", the answer is the same: RAG is the pattern of retrieve → augment → generate. It is not a single model; it is a system composed of a retriever (search), a knowledge base (your data), and a generator (the LLM). The acronym captures the three stages of every RAG pipeline.
How RAG Works: Step by Step#
Understanding RAG requires walking through its six core steps. Each step has design decisions that directly affect answer quality.
Step 1 — Document Ingestion and Chunking#
Your source documents — PDFs, web pages, Confluence pages, databases — are loaded and split into smaller chunks (typically 200–1,000 tokens). Chunk size is a critical lever: too small and you lose context; too large and retrieval precision drops. Advanced pipelines use semantic chunking (splitting at natural topic boundaries) or recursive character splitting with overlap to preserve context across chunk boundaries.
Key decisions: chunk size, overlap, splitting strategy (fixed-length vs. semantic vs. sentence-based), and whether to attach metadata (source URL, page number, section header) to each chunk for later citation.
Step 2 — Embedding and Indexing#
Each chunk is passed through an embedding model (e.g., OpenAI text-embedding-3-small, Cohere embed-english-v3.0, or open-source models like BGE-large) that converts text into a dense vector — a list of ~1,000 floating-point numbers capturing semantic meaning. These vectors are stored in a vector database such as Pinecone, Weaviate, Milvus, or pgvector.
The vector database builds an index (typically HNSW or IVF-PQ) that enables approximate nearest-neighbor search in milliseconds, even across millions of chunks.
Key decisions: embedding model choice (accuracy vs. latency vs. cost), dimensionality, and index type.
Step 3 — Query Embedding and Retrieval#
When a user submits a query, the same embedding model encodes the query into a vector. The vector database then performs a similarity search — usually cosine similarity or dot product — to find the k most similar document chunks (typically k = 5–20). This is the "retrieval" in RAG.
Some systems also use hybrid retrieval, combining dense vector search with sparse keyword search (BM25) to capture both semantic similarity and exact keyword matches. Hybrid retrieval consistently outperforms either method alone, especially for queries containing specific names, IDs, or technical terms.
Key decisions: retrieval method (dense-only vs. hybrid), top-k value, and similarity metric.
Step 4 — Reranking#
The initial retrieval cast a wide net. A reranker narrows it. Rerankers are cross-encoder models (e.g., Cohere Rerank, ColBERT, BGE-reranker) that score each candidate chunk against the query with full attention over both texts simultaneously. This is slower than bi-encoder retrieval but far more accurate.
After reranking, only the top n chunks (typically 3–7) are selected for the final prompt. Reranking is the single highest-impact upgrade for most RAG pipelines: studies consistently show 10–30% improvements in relevance metrics.
Key decisions: reranker model, number of chunks to rerank, and number of chunks to pass to the LLM.
Step 5 — Prompt Construction and Generation#
The selected chunks are injected into a prompt template alongside the user's query. A typical prompt looks like:
Answer the question using only the context below. If the context does not contain
enough information, say "I don't have enough information to answer this."
Context:
{chunk_1}
{chunk_2}
{chunk_3}
Question: {user_query}
Answer:
The LLM (GPT-4, Claude, Gemini, Llama, etc.) then generates a response grounded in the provided context. Because the model can reference the retrieved passages, its answers are factual and can include citations pointing back to source documents.
Key decisions: prompt template, system instructions, and whether to allow the model to refuse when context is insufficient.
Step 6 — Response Delivery and Citation#
The final response is delivered to the user, ideally with inline citations — references to the source document, page, or URL for each claim. This traceability is what makes RAG trustworthy in enterprise settings. Without citations, a RAG system is just another chatbot; with citations, it becomes a verifiable research assistant.
Key decisions: citation format, whether to show source snippets alongside the answer, and how to handle partial matches.
RAG Architecture: The Full Pipeline#
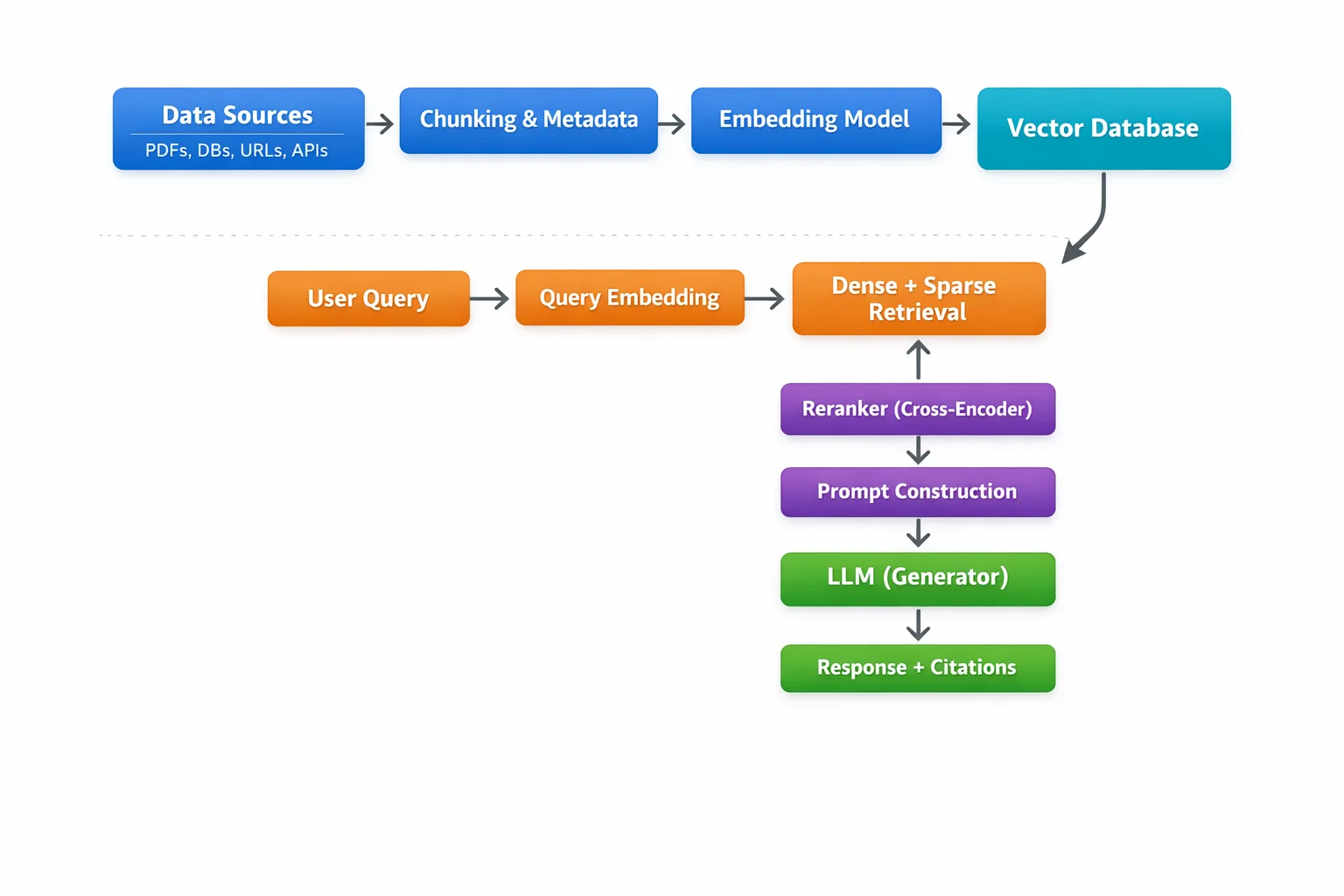
Key Components of a RAG System#
1. Retriever#
The retriever is the search engine inside RAG. Its job is to find the most relevant chunks from the knowledge base given a query. There are three main retrieval strategies:
| Strategy | How It Works | Strengths | Weaknesses |
|---|---|---|---|
| Dense (vector) | Embeds query and chunks; finds nearest neighbors by cosine similarity | Captures semantic meaning; handles paraphrases | Misses exact keyword matches |
| Sparse (BM25) | Keyword-based search using term frequency | Exact match on names, IDs, technical terms | No semantic understanding |
| Hybrid | Combines dense + sparse scores (often with Reciprocal Rank Fusion) | Best of both worlds | More complex to tune |
Most production RAG systems use hybrid retrieval. If you're building RAG today, start with hybrid — it is the single most impactful architectural decision after choosing your LLM.
For a deep dive into retrieval approaches, see our guide to semantic search and the Denser Retriever architecture.
2. Vector Database#
The vector database stores embeddings and supports fast similarity search. Your choices include:
| Database | Type | Best For |
|---|---|---|
| Pinecone | Managed cloud | Teams that want zero ops |
| Weaviate | Open-source / managed | Hybrid search out of the box |
| Milvus | Open-source | Massive scale (billions of vectors) |
| pgvector | PostgreSQL extension | Teams already on Postgres |
| Qdrant | Open-source (Rust) | Low-latency, resource-efficient |
| Chroma | Open-source | Quick prototyping |
If you're evaluating alternatives, check our comparison of Elasticsearch alternatives for search infrastructure.
3. Large Language Model (Generator)#
The LLM is the final reasoning engine. Popular choices for RAG generation:
- GPT-4o / GPT-4.1 — Strong reasoning, widely used, higher cost
- Claude 3.5 Sonnet / Claude 4 — Excellent at following instructions and refusing when context is insufficient
- Gemini 1.5 Pro — Massive context window (up to 1M tokens), useful when you want to skip chunking
- Llama 3 / Mistral — Open-source, deployable on-premise, good for privacy-sensitive workloads
The LLM's job in RAG is constrained generation: answer from the provided context, not from parametric memory. Prompt design is critical here. A poorly prompted LLM will ignore the context and hallucinate anyway, negating the entire purpose of RAG.
4. Reranker#
As described in Step 4, the reranker is a cross-encoder that rescores candidate chunks. Think of retrieval as "recall" and reranking as "precision." The retriever ensures relevant chunks are somewhere in the candidate set; the reranker ensures they're at the top.
Leading rerankers include Cohere Rerank, Jina Reranker, BGE-reranker-v2-m3, and ColBERT. Adding a reranker typically improves answer relevance by 15–30% with minimal latency overhead (50–200ms for reranking 20–50 candidates).
5. Chunking Strategy#
Chunking is the unsung hero of RAG. Bad chunking = bad retrieval = bad answers, no matter how good your LLM is. The main strategies:
- Fixed-size chunking — Split every N characters/tokens with optional overlap. Simple but can break sentences or topics mid-way.
- Sentence-based chunking — Split at sentence boundaries. Better coherence but variable chunk sizes.
- Semantic chunking — Split when the embedding similarity between consecutive sentences drops below a threshold. Preserves topical coherence.
- Recursive chunking — Split by largest delimiter (paragraphs), then by smaller delimiters (sentences), then by characters. Balances coherence and size control.
Best practice: Start with recursive chunking (chunk size ~500 tokens, overlap ~50 tokens) and tune from there. Always attach metadata — source, page, section — to every chunk for citation.
RAG vs Fine-Tuning vs Prompt Engineering#
This is the most common question teams face: should we use RAG, fine-tuning, or just write better prompts? The answer is almost always "use RAG for factual accuracy and fine-tuning for style/behavior" — and often both together.
| Dimension | RAG | Fine-Tuning | Prompt Engineering |
|---|---|---|---|
| What it does | Injects real-time external knowledge | Adapts model weights to your domain | Shapes model behavior via instructions |
| Best for | Factual accuracy, up-to-date data, citations | Tone, format, domain-specific language | Quick tweaks, simple tasks |
| Hallucination risk | Low (answers grounded in retrieved docs) | Still high (model may fabricate facts) | High (model relies on parametric memory) |
| Data freshness | Always current (queries live data) | Frozen at training time | Frozen at training time |
| Cost to build | Moderate (pipeline infrastructure) | High (GPU hours, data prep) | Very low (just text) |
| Cost per query | Moderate (retrieval + generation) | Low (just generation) | Low (just generation) |
| Explainability | High (citations, source tracing) | Low (weights are opaque) | Moderate (prompt is visible) |
| When to use alone | You need accurate, cited, current answers | You need the model to speak your brand voice | You need a quick prototype or simple task |
| When to combine | RAG + fine-tuning = factual + stylized | Fine-tune for style; RAG for facts | Prompt eng. is always part of RAG |
Decision Framework#
- Only need a few-shot examples? → Prompt engineering
- Need the model to adopt a specific tone/format? → Fine-tune, then add RAG
- Need answers grounded in your proprietary data? → RAG (mandatory)
- Need both style and accuracy? → Fine-tune for style + RAG for facts
Read more about building RAG pipelines in our tutorial on building a RAG knowledge base with Claude Code.
RAG Tools and Frameworks#
Frameworks#
| Framework | Description | Best For |
|---|---|---|
| LangChain | The most popular RAG orchestration framework; modular chains, agents, and retrievers | Rapid prototyping and flexible pipelines |
| LlamaIndex | Data-focused framework with excellent indexing and retrieval abstractions | Data ingestion, advanced indexing patterns |
| Haystack | Production-oriented pipeline framework by deepset | Enterprise deployments with strict requirements |
| Denser Retriever | Open-source hybrid retriever with built-in reranking; optimized for production RAG | Teams that want best-in-class retrieval out of the box |
Vector Databases#
As covered above, Pinecone, Weaviate, Milvus, pgvector, Qdrant, and Chroma are the leading options. Choice depends on scale, managed vs. self-hosted preference, and whether you need hybrid search natively.
Managed RAG Platforms#
If you don't want to assemble a pipeline yourself, several platforms offer RAG-as-a-service:
- Denser.ai — End-to-end AI knowledge base with built-in RAG, chatbot, and search. Try the Denser Retriever for open-source retrieval or the AI knowledge base platform for a managed experience.
- Azure AI Search + OpenAI — Microsoft's integrated RAG stack
- Amazon Bedrock Knowledge Bases — AWS-native RAG with multiple LLM options
- Google Vertex AI RAG Engine — Google Cloud's managed RAG offering
For chatbot-specific deployments, explore our roundups of AI chatbot solutions and AI chatbot examples.
Common RAG Failures and How to Fix Them#
RAG is powerful, but it breaks in predictable ways. Here are the seven most common failure modes and their fixes.
Failure 1: Irrelevant Retrieval#
Symptom: The retrieved chunks are off-topic, so the LLM generates a plausible-sounding but wrong answer.
Root cause: Poor embedding model, no hybrid retrieval, or query-chunk semantic mismatch.
Fix: Switch to hybrid retrieval (dense + BM25), upgrade your embedding model, and add a reranker. This combination alone fixes 60–70% of relevance issues.
Failure 2: Lost-in-the-Middle Effect#
Symptom: The LLM ignores chunks placed in the middle of the prompt context, attending only to the first and last few chunks.
Root cause: Well-documented LLM attention bias; models weight beginning and end of context more heavily.
Fix: Place the most relevant chunks at the beginning and end of the context window. Use reranking to ensure the best chunks are positioned strategically. Limit context to 5–7 chunks instead of 20.
Failure 3: Chunk Boundary Problems#
Symptom: Key information is split across two chunks, so neither chunk contains enough context to answer the question.
Root cause: Fixed-size chunking cuts mid-sentence or mid-paragraph.
Fix: Use semantic or recursive chunking with overlap (50–100 tokens). Add parent-document retrieval: store small chunks for search but retrieve the parent document section for context.
Failure 4: Outdated Knowledge Base#
Symptom: The system confidently returns stale information — old policies, deprecated APIs, last quarter's pricing.
Root cause: No pipeline for updating or deleting documents in the vector store.
Fix: Build an automated ingestion pipeline that re-indexes changed documents on a schedule. Use metadata filters (e.g., date > 2025-01-01) to exclude outdated content at query time.
Failure 5: Query Misunderstanding#
Symptom: The user's query is vague, ambiguous, or uses different terminology than the documents, leading to poor retrieval.
Root cause: The embedding model can't bridge the vocabulary gap between query and documents.
Fix: Implement query transformation: use an LLM to rewrite or expand the user's query before retrieval. Techniques include HyDE (Hypothetical Document Embedding), multi-query generation, and step-back prompting.
Failure 6: Over-Reliance on LLM Parametric Memory#
Symptom: The LLM answers from its training data instead of the retrieved context, producing hallucinations even with RAG.
Root cause: Weak prompt instructions that don't force the model to use the context.
Fix: Strengthen the system prompt: "Answer using ONLY the provided context. If the context does not contain the answer, respond with 'I don't have enough information.' Do not use any external knowledge." Test with Claude or GPT-4, which follow such instructions more reliably than smaller models.
Failure 7: Latency Blow-Up#
Symptom: End-to-end response time exceeds 10–30 seconds, making the system unusable for real-time chat.
Root cause: Too many retrieval steps, large reranking batches, or oversized prompts.
Fix: Reduce top-k at retrieval (20 → 10), reduce reranking candidates, cache frequent queries, use smaller/faster embedding models for retrieval while keeping a larger model for generation, and consider streaming the LLM output.
Evaluating RAG Quality#
You can't improve what you don't measure. RAG evaluation requires assessing both retrieval quality and generation quality.
Core Metrics#
| Metric | What It Measures | How to Compute |
|---|---|---|
| Context Precision | Are the retrieved chunks relevant to the query? | Grade each chunk as relevant/irrelevant; compute precision@k |
| Context Recall | Did retrieval find all the information needed to answer? | Compare chunks against a ground-truth answer; check coverage |
| Faithfulness | Is the generated answer faithful to the retrieved context (no hallucination)? | Decompose answer into claims; verify each claim against context |
| Answer Relevance | Does the answer actually address the question? | LLM-as-judge or embedding similarity between answer and question |
| Answer Correctness | Is the answer factually correct? | Compare against ground-truth reference; use LLM-as-judge or human eval |
Evaluation Frameworks#
- RAGAS (Retrieval Augmented Generation Assessment) — The most widely used open-source framework; computes faithfulness, answer relevance, context precision, and context recall automatically using LLMs as judges.
- TruLens — Provides similar metrics with a dashboard for visual tracking of RAG app quality over time.
- ARES — Automated RAG Evaluation System using lightweight LLM judges fine-tuned on a small set of human annotations.
Evaluation Best Practices#
- Build a golden test set of 50–200 question-answer pairs with ground truth. This is your benchmark.
- Run evaluations on every pipeline change — new embedding model, different chunk size, added reranker, etc.
- Track all five metrics — optimizing only context precision can hurt recall; optimizing only faithfulness can make answers too conservative.
- Use LLM-as-judge for speed, but validate with human evaluation on a sample.
- Monitor in production — log queries, retrieved chunks, and answers; sample and review weekly.
Industry Use Cases#
Customer Support#
RAG-powered chatbots answer customer questions by retrieving from product documentation, FAQs, ticket history, and policy pages. The result: accurate answers with links to source articles, reducing escalation rates by 30–50%.
Example: A SaaS company indexes its help center, changelog, and status page. When a user asks "Why is my webhook failing?", the RAG system retrieves the relevant troubleshooting article and generates a step-by-step answer citing the exact doc.
Legal#
Law firms and legal departments use RAG to search case law, contracts, and regulatory documents. RAG ensures answers are grounded in actual legal text — critical when a hallucinated statute could have real consequences.
Example: A paralegal asks "What are the data breach notification requirements under GDPR Article 33?" The system retrieves the article text and relevant guidance, generating an answer with direct citations to the regulation.
Healthcare#
Clinical RAG systems retrieve from medical literature, drug databases, and institutional protocols to assist clinicians. Accuracy is non-negotiable; every claim must trace back to a published source.
Example: A physician queries "What are the contraindications for metformin?" The system retrieves relevant drug monograph sections and clinical guidelines, presenting a cited summary.
E-Commerce#
Product recommendation and support chatbots use RAG to search product catalogs, reviews, sizing guides, and return policies. This enables natural-language shopping: "I need a waterproof hiking boot under $120" retrieves matching products with specs.
Example: An outdoor retailer's chatbot retrieves product pages, review summaries, and inventory status to answer "Is the X200 jacket true to size?" with specific review citations.
SaaS and Enterprise Internal Tools#
Companies index internal wikis, Slack conversations, meeting notes, and code documentation. RAG-powered internal search lets employees find answers without pinging colleagues, saving hours per week.
Example: A new engineer asks "How do I set up the staging environment?" The RAG system retrieves the onboarding wiki page, the relevant runbook, and recent Slack threads about staging issues.
For more on deploying RAG in enterprise settings, see our guide to AI knowledge bases.
What's Next: Agentic RAG and Multimodal RAG#
RAG in 2025–2026 is evolving beyond single-turn retrieve-and-generate into more sophisticated architectures.
Agentic RAG#
Traditional RAG is passive: one retrieval step, one generation. Agentic RAG gives the system autonomy to plan, retrieve iteratively, use tools, and self-correct.
In an agentic RAG pipeline:
- The agent decomposes a complex question into sub-questions.
- It retrieves for each sub-question independently.
- It evaluates whether retrieved context is sufficient — and if not, reformulates queries and retrieves again.
- It may call external tools — calculators, SQL queries, web search — to fill gaps.
- It synthesizes all gathered information into a coherent answer.
Agentic RAG dramatically improves performance on multi-hop questions ("Compare Q3 revenue for Product A vs. Product B and explain the difference") where single-pass retrieval fails because no single chunk contains all the needed information.
Frameworks like LangGraph, CrewAI, and the Denser Retriever's agentic mode support this pattern.
Multimodal RAG#
Most RAG systems today handle text only. Multimodal RAG extends retrieval and generation to images, tables, charts, audio, and video.
Approaches include:
- Embed images alongside text using multimodal embedding models (e.g., CLIP, Jina CLIP) so that a text query can retrieve relevant images and vice versa.
- Extract and embed table content separately, preserving structure for precise retrieval of numerical data.
- Use vision-language models (GPT-4o, Gemini Pro Vision, LLaVA) as the generator so they can reason over retrieved images, not just text.
Multimodal RAG is especially valuable in medical imaging (retrieve similar X-rays), e-commerce (retrieve product images), and technical documentation (retrieve diagrams and schematics).
Denser Retriever: Open-Source RAG Infrastructure#
If you're building a RAG system, Denser Retriever gives you production-grade retrieval out of the box — no need to stitch together embedding models, vector databases, and rerankers yourself.
What Makes Denser Retriever Different#
| Feature | Denser Retriever | Typical DIY Pipeline |
|---|---|---|
| Hybrid retrieval | Built-in (dense + sparse + rerank) | Requires custom integration |
| Reranking | Integrated cross-encoder reranker | Separate model + glue code |
| Embedding model | Included, optimized for retrieval | Choose, evaluate, integrate yourself |
| Vector database support | Milvus, Weaviate, pgvector, and more | Pick one, write adapters |
| Open source | Full Apache 2.0 license | N/A |
| Production-ready | Used at scale by Denser.ai users | You bear the integration burden |
Getting Started#
- Install: pip install denser-retriever
- Connect your data source (PDFs, URLs, databases)
- Configure your vector database
- Query: Denser Retriever handles embedding, hybrid search, and reranking automatically
Explore the full documentation and examples at retriever.denser.ai or read our Denser Retriever deep dive.
Denser Retriever is also the retrieval backbone of the Denser.ai AI knowledge base platform, which provides an end-to-end managed experience — ingest documents, configure chatbots, and deploy RAG-powered search without writing pipeline code.
Get Started With RAG#
Ready to build your first RAG system? Here's a practical path:
- Define your use case. What questions should the system answer? What data sources does it need?
- Choose a framework. LangChain or LlamaIndex for flexibility; Denser Retriever for best-in-class retrieval; a managed platform if you want to skip infrastructure.
- Prepare your data. Clean, deduplicate, and organize your documents. Metadata matters — tag everything with source, date, and section.
- Chunk and embed. Start with recursive chunking (~500 tokens, ~50 overlap) and a strong embedding model (BGE-large or OpenAI text-embedding-3-small).
- Set up hybrid retrieval + reranking. This is non-negotiable for production quality. Dense-only retrieval will disappoint.
- Choose your LLM. Start with GPT-4o or Claude 3.5 Sonnet for quality; optimize to smaller models later.
- Evaluate. Build a golden test set. Run RAGAS. Iterate on chunk size, retrieval parameters, and prompt design.
- Deploy and monitor. Log every query, retrieval result, and answer. Review a sample weekly. Treat RAG quality as an ongoing operational concern, not a one-time project.
For a hands-on walkthrough, follow our tutorial on building a RAG knowledge base with Claude Code.
FAQs#
What is RAG in AI?#
RAG (Retrieval-Augmented Generation) in AI is a system architecture where a language model retrieves relevant documents from a knowledge base before generating a response. Instead of relying only on the model's training data, RAG grounds answers in real, retrieved content — making them more accurate and verifiable.
What does RAG stand for?#
RAG stands for Retrieval-Augmented Generation. The three words describe the pipeline: retrieve relevant documents, augment the LLM prompt with them, and generate a grounded response.
RAG meaning in AI#
In AI, RAG means a pattern where an LLM is paired with a retrieval system (usually a vector database with semantic search) so that every generated answer is informed by actual documents from your data. The "meaning" of RAG is essentially: look it up before you answer.
How does RAG work?#
RAG works in six steps: (1) documents are chunked and embedded into vectors, (2) vectors are stored in a vector database, (3) a user query is embedded, (4) the vector database returns the most similar chunks, (5) a reranker narrows the results, and (6) the top chunks are inserted into the LLM prompt alongside the query, and the LLM generates a cited answer.
RAG vs fine-tuning#
RAG retrieves external knowledge at query time; fine-tuning modifies the model's internal weights on training data. RAG is best for factual accuracy and data freshness; fine-tuning is best for style, tone, and format. In production, many teams fine-tune for behavior and use RAG for knowledge — they are complementary, not competing approaches.
Is RAG better than fine-tuning?#
Neither is universally "better." RAG is better when you need up-to-date, cited, accurate answers from specific data sources. Fine-tuning is better when you need the model to adopt a specific voice, format, or domain language. Most production systems benefit from both: fine-tune for style, RAG for facts.
Do I need a vector database for RAG?#
In most cases, yes. A vector database enables semantic similarity search, which is the foundation of dense retrieval in RAG. You can build RAG with only keyword search (BM25), but you'll sacrifice semantic understanding. Hybrid retrieval (dense vectors + keyword search) consistently outperforms either alone, and that requires a vector database. Alternatives like pgvector let you add vector search to an existing PostgreSQL database.
How accurate is RAG?#
RAG accuracy depends on retrieval quality, prompt design, and the LLM's faithfulness to context. With hybrid retrieval + reranking + a strong LLM, RAG systems can achieve 85–95% faithfulness (answers grounded in context) on well-structured domains. However, accuracy degrades when the knowledge base is outdated, chunking is poor, or the query is ambiguous. Continuous evaluation with frameworks like RAGAS is essential.
Explore More Resources#
- RAG Explained: A Plain-English Guide — A beginner-friendly primer on retrieval augmented generation
- Build a RAG Knowledge Base with Claude Code — Hands-on tutorial for deploying RAG end to end
- Denser Retriever: Open-Source Hybrid Retrieval — Deep dive into the retrieval engine that powers Denser.ai
- Semantic Search Explained — Understanding vector search and embedding models
- Elasticsearch Alternatives for Modern Search — Comparing vector databases and search engines
- Building an AI Knowledge Base — From documents to production RAG-powered search
- AI Chatbot Solutions Compared — Choosing the right chatbot platform for your needs
- AI Chatbot Examples in Production — Real-world deployments and what they get right
- Denser Retriever Documentation — API reference, quickstart guides, and integration examples