RAG Explained: A Plain-English Guide to Retrieval Augmented Generation (2026)

Retrieval augmented generation (RAG) is a method for making a large language model (LLM) answer questions from specific, trustworthy knowledge — your documents, help center, codebase, or product data — instead of relying only on what it memorized during training. The model retrieves the relevant passages first, then generates an answer grounded in those passages, with citations you can check.
The payoff is direct: answers that are current, sourced, and easy to verify — without retraining the model every time your knowledge changes. This guide explains how RAG works, where it beats fine-tuning, the components of a RAG pipeline, and how to choose chunking and search strategies.
Want the complete guide? This is a plain-English primer. For the full pillar guide — RAG frameworks, architecture choices, and a deeper implementation walkthrough — read What is Retrieval-Augmented Generation (RAG)?.
Key takeaways#
- RAG = retrieval + generation. An LLM sees your documents only for the current question, then answers with citations.
- Use RAG when knowledge changes often or accuracy and citations matter. Use fine-tuning to change style, format, or domain fluency.
- Retrieval quality decides answer quality. Chunking strategy and hybrid search are where most RAG systems win or lose.
- RAG is cheaper and faster to update than fine-tuning — you swap documents, not model weights.
What is retrieval augmented generation (RAG)?#
RAG is a two-stage pattern for building AI answers:
- Retrieval. A search step finds the chunks of text in your knowledge base that best match the question. This is usually a vector/embedding search, often combined with keyword search (hybrid search) and a reranking step.
- Generation. Those retrieved chunks are placed into the LLM's prompt as context. The model then writes an answer that is grounded in — and cites — those chunks.
The defining trait is that the model is not recalling facts from memory alone. It is reacting to passages you surface for this question, which means you can correct a wrong answer by fixing the source document rather than retraining anything.
Why RAG matters in 2026#
Plain LLMs hallucinate because they generate plausible text with no provenance. RAG narrows the model's job to "read these passages and answer," which is a far easier and more reliable task than "recall everything about the world." For enterprise search, customer support, and internal knowledge bases, that grounding is the difference between a tool people trust and one they disable.
How RAG works (step by step)#
A production RAG pipeline has five stages:
- Ingest. Load documents (PDFs, web pages, Notion, Slack, code). Clean and normalize them.
- Chunk. Split documents into smaller passages. Chunk size and overlap determine whether the retrieved context is complete. See our deep dive in RAG chunking strategies.
- Embed & index. Convert chunks into vector embeddings and store them in a vector database, usually alongside the original text for keyword search.
- Retrieve. At query time, embed the question and search the index. Hybrid search for RAG — combining dense vector search with BM25/keyword search — consistently outperforms either method alone.
- Generate. Insert the top retrieved chunks into the prompt and let the LLM answer with citations.
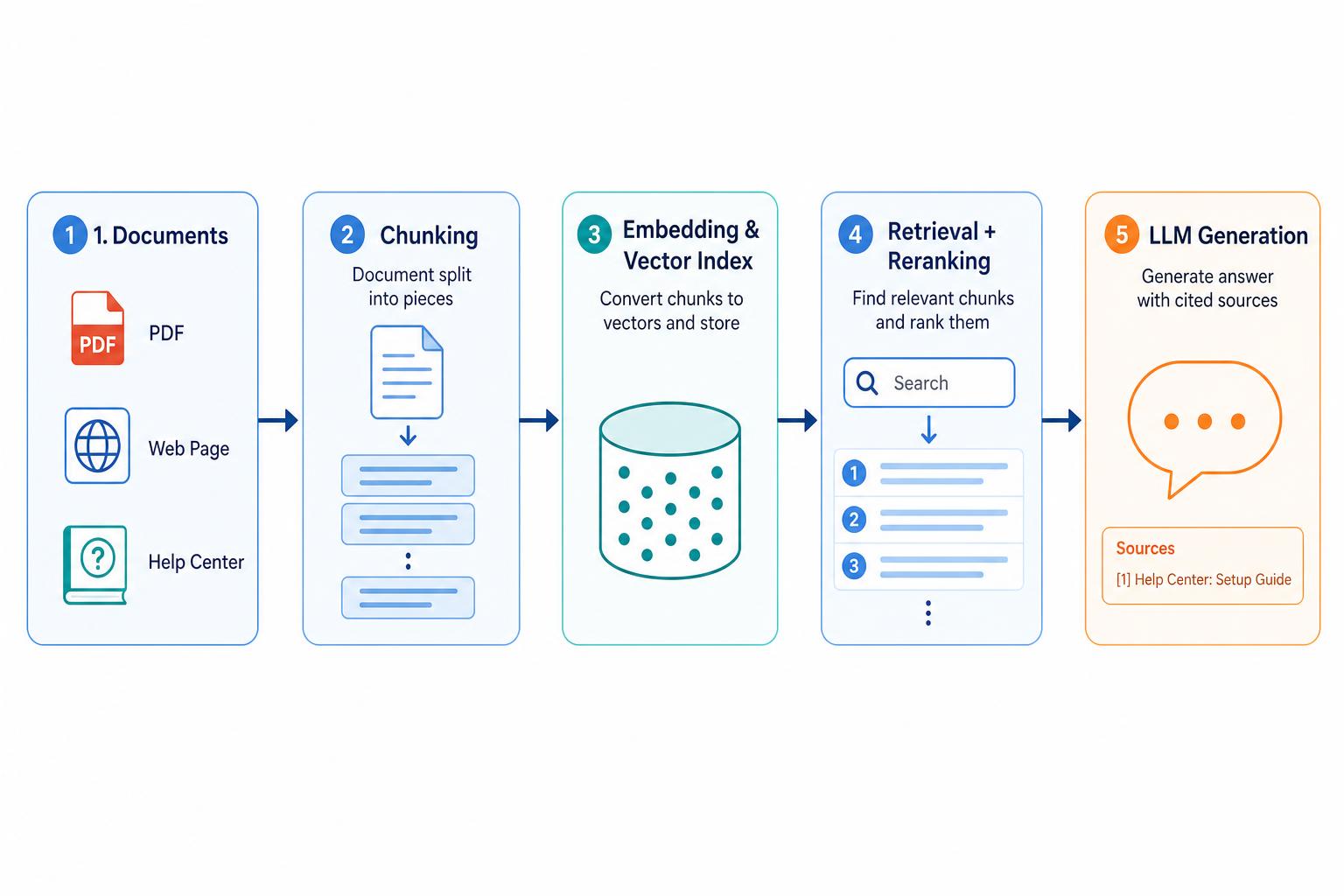
A reranker often sits between steps 4 and 5, reordering candidates by true relevance rather than raw similarity. This single addition is one of the highest-ROI upgrades in a RAG system.
RAG vs fine-tuning vs prompt engineering#
These aren't rivals — they solve different problems.
| Method | Best for | Cost to update | Changes knowledge? | Changes style/format? |
|---|---|---|---|---|
| Prompt engineering | Quick, broad instructions | Near zero (edit prompt) | No | Lightly |
| RAG | Current, sourced knowledge; citations | Low (swap documents) | Yes | No |
| Fine-tuning | Tone, output format, domain fluency | High (retrain weights) | Indirectly | Yes |
Rule of thumb: if the problem is "the model doesn't know the latest facts," reach for RAG. If the problem is "the model writes in the wrong voice or format," reach for fine-tuning. Many production systems use both — fine-tune for style, RAG for facts. For a fuller comparison, see RAG vs fine-tuning.
The core components of a RAG system#
- Embedding model — turns text into vectors. Quality here sets the ceiling for retrieval.
- Vector store — holds the embeddings (pgvector, Pinecone, Weaviate, Qdrant, etc.).
- Retriever — runs the query search and (optionally) reranks results. The Denser Retriever is built specifically for this step.
- LLM — generates the cited answer from the retrieved context.
- Knowledge base / connectors — the ingestion layer that keeps documents synced and fresh.
RAG chunking: why it controls answer quality#
If chunks are too small, the model loses context. If they're too big, relevance signals get diluted and you waste context window. Good chunking keeps each passage self-contained and topical.
Common strategies include fixed-size chunks, sentence/paragraph-aware splitting, semantic chunking, and contextual chunking (which prepends document-level context to each chunk). The right choice depends on your document types — legal prose, code, and tables each need different treatment. We cover the tradeoffs in RAG chunking strategies.
When should you use RAG?#
Reach for RAG when you need:
- Up-to-date answers from documents that change — policies, product docs, support articles.
- Citations and auditability — legal, compliance, finance, healthcare use cases.
- Private or proprietary knowledge an off-the-shelf LLM was never trained on.
- Cost-efficient updates — fixing a doc is cheaper than retraining a model.
Skip RAG (or pair it with fine-tuning) when the job is mainly to change how the model behaves, not what it knows.
Build a RAG knowledge base with Denser#
Denser handles the RAG pipeline end to end — ingestion, chunking, hybrid retrieval, reranking, and cited generation — so you can point it at your documents and get a chat assistant that answers from your data with sources.
If you're starting from raw documents, build a RAG knowledge base walks through the setup, and the Denser Retriever is the retrieval layer you can swap into an existing stack.
Conclusion#
Retrieval augmented generation is the standard pattern for making LLMs trustworthy on your own data: retrieve the right passages, then generate a cited answer. The bottleneck for most teams is retrieval quality — chunking and hybrid search — not the LLM. Get those right and RAG becomes a reliable foundation for enterprise search, support, and internal knowledge.
Denser Chat gives you all of this as a managed RAG solution — no pipeline to build or maintain. Point it at your documents and get a chat assistant that answers from your data with citations. Get started with Denser Chat.
FAQs About Retrieval Augmented Generation#
What is retrieval augmented generation (RAG)?#
RAG is a two-step technique where a system first retrieves passages from your own documents that match a question, then feeds them to an LLM so it can generate a cited, grounded answer instead of relying on memorized training data.
How does RAG work?#
RAG works by ingesting and chunking documents, embedding and indexing them, retrieving the most relevant chunks for a given query (often with hybrid search + reranking), and passing those chunks to an LLM to generate a sourced answer.
What is the difference between RAG and fine-tuning?#
RAG updates what the model knows by surfacing new documents at query time; fine-tuning updates how the model behaves by changing its weights. Use RAG for current, citable knowledge; use fine-tuning for tone, format, and domain fluency.
When should I use RAG?#
Use RAG when answers must be current, sourced, and based on private or frequently updated knowledge — for example support docs, internal knowledge bases, legal research, and enterprise search.
What is a RAG chunking strategy?#
A chunking strategy defines how documents are split into passages before indexing. The goal is to keep each chunk self-contained and topically coherent so retrieval returns complete, relevant context. See our RAG chunking strategies guide.