LLM Wiki: Karpathy's Idea for AI Knowledge Bases

On April 4, 2026, Andrej Karpathy — OpenAI co-founder, former Tesla AI director, and one of the most influential voices in modern AI — quietly published a GitHub gist titled simply "llm-wiki". It wasn't a product launch. It wasn't a research paper. It was, in his own words, "an idea file" — a one-page pattern for building personal knowledge bases on top of LLMs.
Within two weeks the gist had crossed 5,000 stars, 4,000+ forks, hundreds of comments, dozens of GitHub re-implementations, write-ups in VentureBeat and across Medium and Substack, and even commercial SaaS products positioning themselves around the pattern.
For a company like ours — Denser.ai builds AI chatbots and RAG systems on top of customer knowledge bases for a living — this thread is impossible to ignore. The idea both validates and challenges the way the entire industry (us included) has been doing things.
This post does three things. First, we walk through the discussion and the top 10 most-starred GitHub projects that have emerged around the LLM Wiki idea. Second, we distill what's actually valuable in the pattern — the product principles worth keeping, separate from the hype. Third, we share where we think it pushes our own roadmap at Denser.ai.
The core idea, in 30 seconds#
Karpathy's framing is best captured in his own analogy: today's RAG systems are like cooking a meal from scratch every time you're hungry. Each query re-retrieves chunks, re-reads them, re-synthesizes an answer. Nothing accumulates.
LLM Wiki proposes the opposite: the LLM compiles raw sources into a structured, persistent, interlinked Markdown wiki — and then queries the wiki instead of the raw sources. When new sources arrive, the wiki is updated, cross-references are revised, contradictions are flagged. Knowledge compounds.
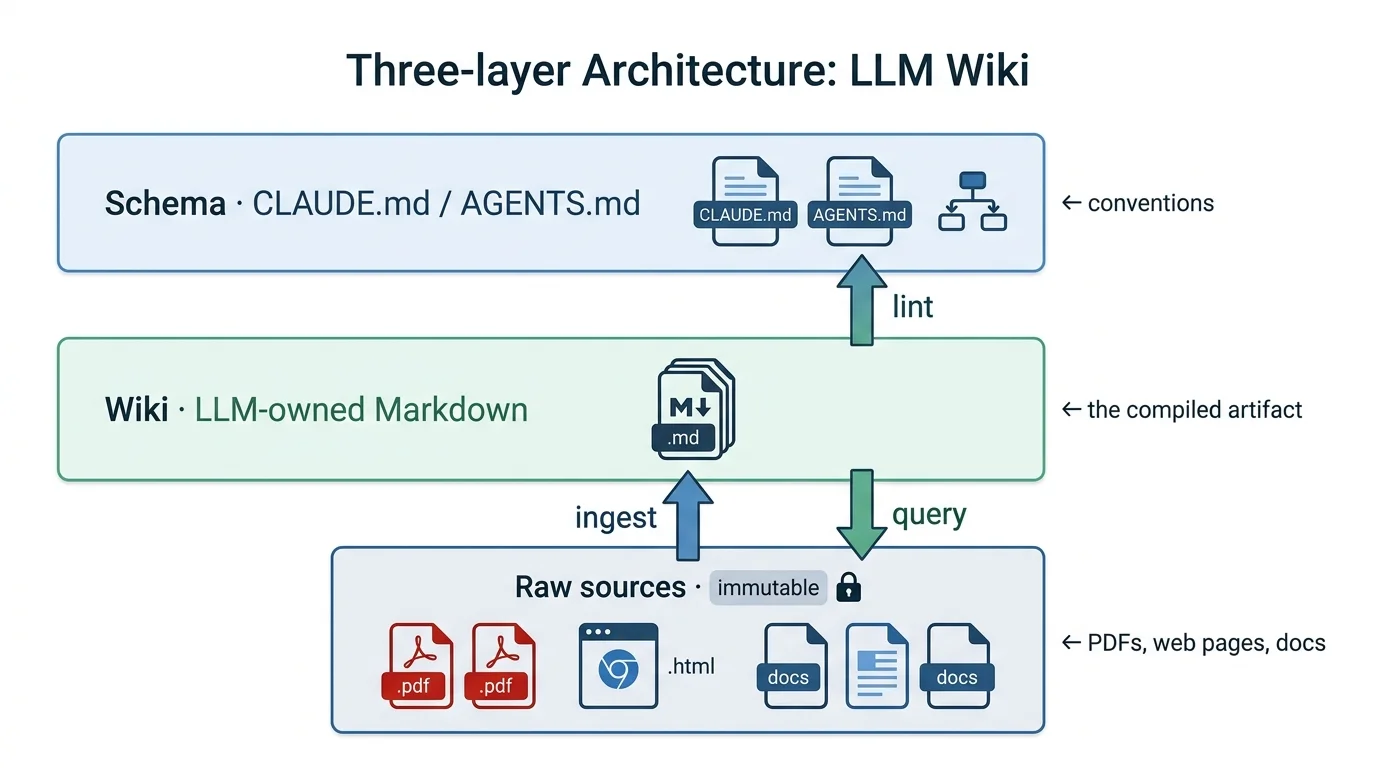
The architecture has three layers — raw sources (immutable), the wiki (LLM-owned), and a schema file like CLAUDE.md or AGENTS.md (the conventions). And three operations — ingest, query, and lint. That's the whole pattern.
Karpathy's pithiest line:

Part 1: The discussion and the top 10 projects#
The shape of the conversation#
The comment thread on Karpathy's gist alone is worth reading as a snapshot of where the AI tooling community is right now. A few threads from the gist's comments stood out:
From the gist's comments, the most useful constructive thread was the Zettelkasten extension by @403-html, who took the bare pattern and added what the gist deliberately leaves out: a citation model with footnotes, a strict type taxonomy (topics, projects, syntheses, questions), graph topology constraints, and explicit handling for contradictions. The takeaway: the bare pattern works, but anyone running it seriously ends up reinventing classical knowledge-management discipline.
Also in the gist's comments, the most pointed critiques came from @gnusupport and @LudoE11, who argued that the pattern collapses past ~1,000 files, that LLM-only maintenance leads to compounding hallucinations, and that calling a folder of AI-written Markdown a "wiki" is a category error since no humans collaborate on it. These critiques are sharp and largely fair — and they're exactly what the production-grade implementations are now trying to solve.
The framing that's done the most work is "knowledge as compiled code." Picked up by Plaban Nayak in Level Up Coding and others, it captures the shift from stateless retrieval to stateful, compounding knowledge. The wiki is the build artifact. Mainstream press coverage was led by VentureBeat, framing it as a direct challenge to the SaaS-heavy Notion / Google Docs model and to the entire vector-DB-first orthodoxy of modern RAG.
The top 10 most-starred GitHub implementations#
Within roughly two weeks, dozens of implementations appeared. Below are the ten most-starred projects that explicitly position themselves as Karpathy LLM Wiki implementations, ranked by GitHub star count as of April 16, 2026. Star counts are approximate and growing daily.
1. SamurAIGPT/llm-wiki-agent — ~1,965 stars A multi-platform wiki agent compatible with Claude Code, Codex/OpenCode, and Gemini CLI via separate schema files. Most notable design choice: it detects contradictions at ingest time rather than deferring them to a later lint pass. No API key required — uses your existing coding agent's session.
2. AgriciDaniel/claude-obsidian — ~1,480 stars The most visually polished implementation. Ten specialized skills covering ingest, query, lint, save (file your current chat to the vault), and /autoresearch (an autonomous research loop). Adds a "hot cache" layer — at the end of every session it updates a recent-context summary so the next session resumes with full context, no recap needed. Six pre-built modes (Website, GitHub, Business, Personal, Research, Book/Course).
3. nashsu/llm_wiki — ~1,473 stars A cross-platform desktop application — not a CLI or skill — that turns documents into an interlinked knowledge base automatically. Features a four-signal relevance model and uses Louvain community detection for automatic knowledge clustering. The desktop-app form factor makes it the most accessible option for non-developers in the top 10.
4. ballred/obsidian-claude-pkm — ~1,352 stars A complete starter kit for an Obsidian + Claude Code personal knowledge management system. Distinctive feature: a "goal cascade" PKM that links a 3-year vision to daily tasks, with PostToolUse auto-commit hooks and an /adopt command for importing existing vaults non-destructively. Skews more "life operating system" than "research wiki."
5. lucasastorian/llmwiki — ~459 stars Open-source implementation that ships an MCP server so Claude.ai (the consumer product, not just Claude Code) can directly search, read, write, and lint a persistent knowledge vault. Hosted version available at llmwiki.app. Document viewer for source review built in. A great fit for users who want the pattern without leaving the standard Claude.ai chat interface.
6. Astro-Han/karpathy-llm-wiki — ~446 stars Packages the pattern as a single installable Agent Skill compatible with Claude Code, Cursor, Codex, and other Agent-Skills tools. The README is built from a real production knowledge base of 94 articles and 99 sources, maintained daily since the pattern was published. Battle-tested workflow rules.
7. Ar9av/obsidian-wiki — ~411 stars A multi-agent compatible framework with one notable engineering choice: a single setup script (setup.sh) that deploys the wiki skills to nine different coding agents simultaneously via symlinks. Covers Claude Code, Cursor, Windsurf, Codex, Gemini/Antigravity, Hermes, OpenClaw, GitHub Copilot, and Kilocode. Also includes a delta-tracking manifest (only new or changed sources get re-ingested) and vision-based ingestion for screenshots, slides, and diagrams.
8. lewislulu/llm-wiki-skill — ~298 stars Most distinctive feature: an Obsidian audit plugin plus a local Node.js web preview server. Reviewers can highlight wiki text right in the browser or in Obsidian, leave structured comments with severity levels, and the agent picks them up as feedback to act on. Closes the human-in-the-loop gap that the bare gist leaves open.
9. skyllwt/OmegaWiki — ~269 stars The most ambitious extension. A typed knowledge graph with nine entity types and nine edge types (extends, contradicts, supports, inspired_by, tested_by, invalidates, supersedes, addresses_gap, derived_from). Twenty-three Claude Code skills covering the full research lifecycle from arXiv ingestion through to drafting paper responses to reviewers. Bilingual EN+CN. The closest thing to an "LLM Wiki for serious academic research."
10. nvk/llm-wiki — ~220 stars A Claude Code / Codex plugin (also portable via AGENTS.md for any other LLM agent) that takes a different angle on the pattern: instead of one agent maintaining one wiki, /wiki:research launches 5–10 parallel agents and keeps drilling into subtopics across multiple rounds until a time budget is hit. A dedicated thesis mode (/wiki:research --mode thesis) collects evidence for and against a claim and returns a verdict — built specifically for contested questions where naive retrieval would confirm whatever you typed in.
What the projects converge on#
Reading across these ten implementations, a clear v2 of the pattern is forming. The original gist is deliberately minimal — flat Markdown, an index.md, a log.md, and "your LLM can figure out the rest." The production-grade extensions consistently add the same handful of things:
- Hybrid retrieval — BM25 + vector search + graph traversal, with Reciprocal Rank Fusion. The flat-index approach scales to maybe 200–500 documents before it starts to fray.
- Typed entities and typed relationships — not just [[wikilinks]] but a real ontology (extends, contradicts, supersedes, derived_from).
- Confidence scoring and supersession — every claim carries a confidence value that decays with time and strengthens with reinforcement; new contradicting facts explicitly supersede old ones rather than silently coexist.
- Human-in-the-loop checkpoints — anything below a confidence threshold queues for human review instead of auto-merging.
- Inline citations back to immutable sources — so the wiki is always re-derivable from raw sources and provenance is never lost.
- Lint as a first-class operation — orphan detection, contradiction detection, stale-claim detection, missing-cross-reference detection.
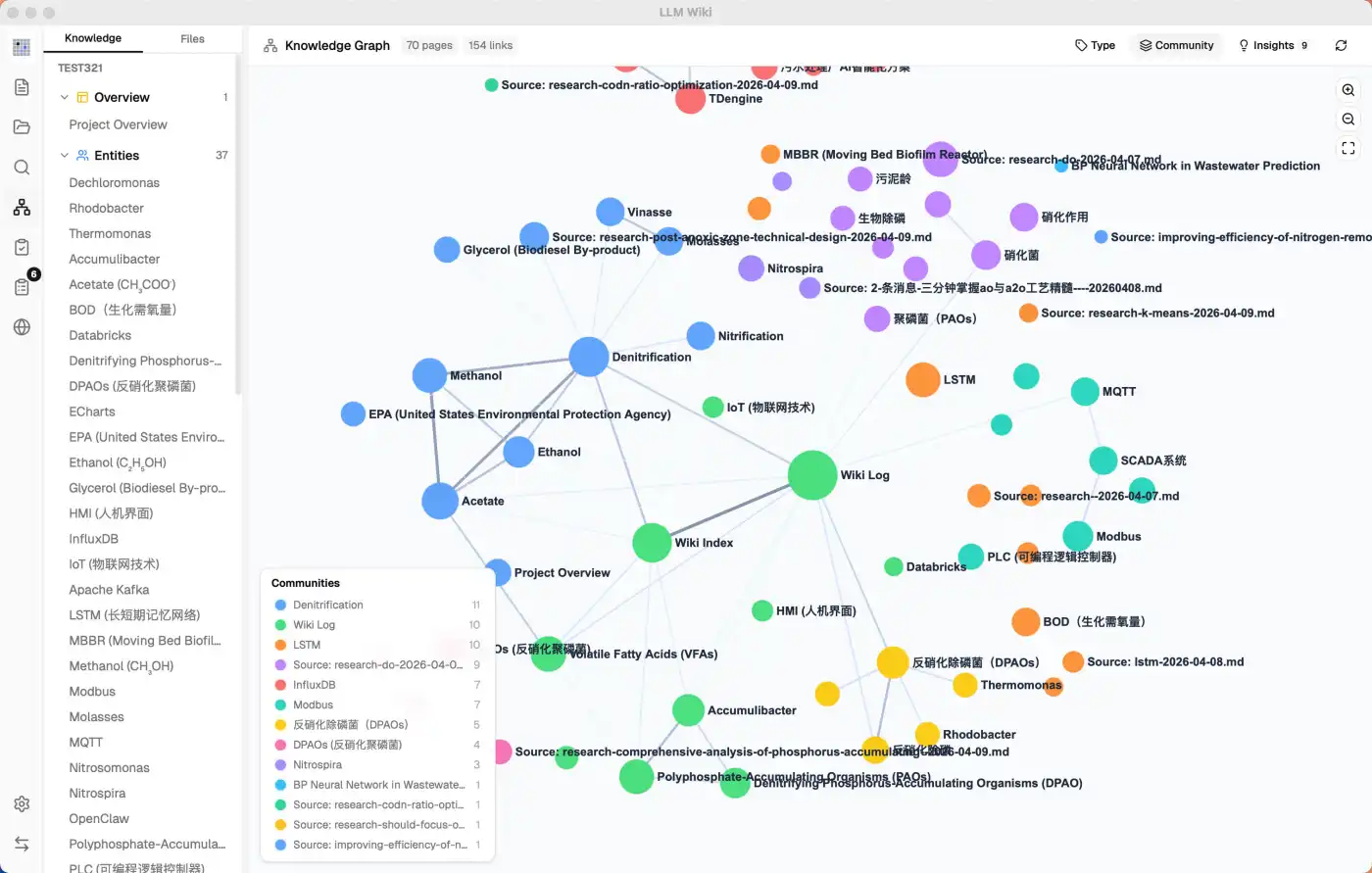
That last one is interesting. In Karpathy's gist, lint is presented almost as a maintenance chore. In practice — see the 200K-line Go codebase write-up where the first compilation pass surfaced 10 real contradictions in the project's existing documentation — it turned out to be one of the most valuable outputs. A consistency linter for prose is something humans simply have not had before.
The commercial layer#
Beyond the open-source projects, a commercial layer is forming around the same pattern. Graphite Atlas positions itself as a typed property-graph product — the answer to flat Markdown's limitations for business use cases. Synthadoc offers structured JSON schemas, confidence scoring per claim, and HITL queueing for production deployments. Dume Cowork rebuilds the workflow for non-developers — point it at your files, no terminal required. And tools that predate the pattern but slot neatly into it — like Cherry Studio (43k+ stars), an AI desktop client with a built-in knowledge base — are being held up by skeptics as evidence that mature, polished tooling for this use case already exists.
Part 2: The product values worth keeping#
Strip the discussion of its hype and its skepticism, and a small set of genuine product principles fall out. These aren't tied to Markdown, Obsidian, or any specific stack — they're properties of any AI-powered knowledge system worth building.
1. Compile once, query many. The single biggest insight is that meaningful synthesis should happen at ingest time, not at query time. RAG re-derives answers on every question. A compiled artifact stays useful, scales answer quality, and dramatically reduces per-query cost and latency.
2. Knowledge should compound. Each new source should make the whole system smarter, not just retrievable. That requires the system to actively update existing pages, revise summaries, and flag conflicts when new material arrives — not just append a new chunk to a vector index.
3. Provenance is non-negotiable. Raw sources stay immutable. Every derived claim points back to a source. This is what lets you re-derive the wiki from scratch, audit the system, and trust the answers. It's also what stops compounding hallucination in its tracks.
4. Human-readable beats opaque. A folder of Markdown files you can open, diff, search, version with git, and read with no special tooling is fundamentally more durable than a proprietary vector index. The wiki survives the AI provider; the vector store doesn't.
5. The bookkeeping should be free. Wikis traditionally fail because the maintenance burden grows faster than the value — humans abandon them. LLMs don't get bored, can touch 15 files in one pass, and never forget to update a cross-reference. The maintenance economics flip.
6. Consistency-checking is a feature, not a chore. "Lint" — finding contradictions, stale claims, orphan pages, missing concepts — turns out to be one of the most useful things an LLM can do over an existing knowledge base. It's a class of work humans simply could not do at scale before.
7. The shape of the answer is part of the answer. The same query might deserve a Markdown page, a comparison table, a slide deck, or a chart. Good answers can also be filed back into the knowledge base as new pages. Exploration compounds, not just ingestion.
These principles, taken together, are what's genuinely new. The Markdown-and-Obsidian implementation is just one expression of them.
Part 3: What this means for Denser.ai#
We build AI chatbots and document-intelligence products that sit on top of customer knowledge bases — websites, PDFs, Google Drive folders, internal wikis, structured databases. Today, like most of the industry, the heart of our system is a high-quality RAG pipeline (Denser Retriever) with chunk-level retrieval, hybrid search, and reranking.
The LLM Wiki pattern doesn't ask us to throw any of that out. It asks us to add a layer above it.
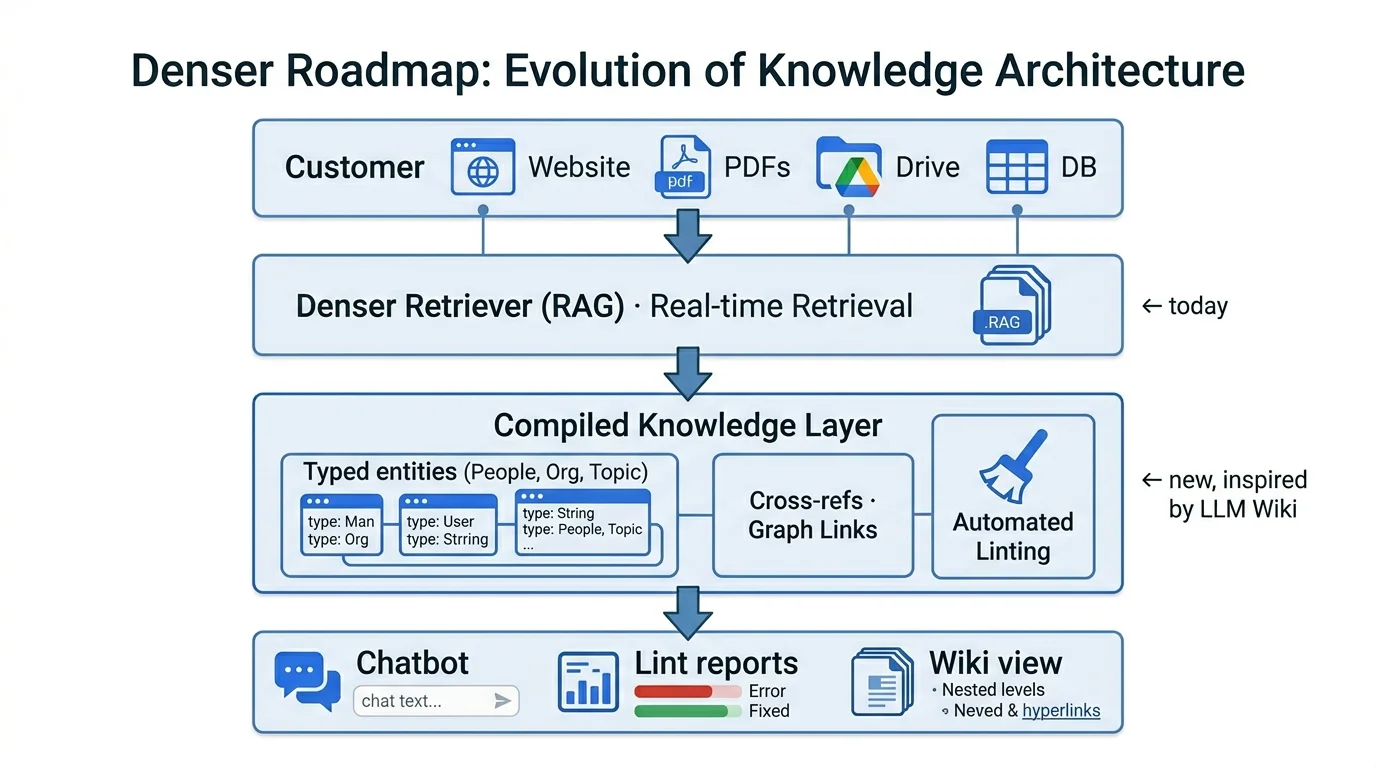
Concretely, here's where we think the inspiration translates into product:
A "compiled knowledge" layer above raw RAG. When a customer connects a website or a folder, today we crawl, chunk, embed, and store. Tomorrow, we additionally compile: extract entities, build a structured map of products, services, policies, FAQs, and the relationships between them. The chatbot answers from this compiled layer first, falling back to chunk retrieval only when needed. Ingest is heavier; queries are faster, cheaper, and more consistent.
Auto-generated "About this knowledge base" pages. A short, structured summary of what's actually in the knowledge base — top entities, most-referenced concepts, coverage gaps, recent additions. Useful for the customer (so they know what their bot can and can't answer), useful for the bot (a free index), and incidentally great for SEO when published.
Lint as a customer-facing feature. This is the most exciting one. After ingest, automatically surface to the customer: "Your refund policy page contradicts your terms of service on this point." "Three product pages reference a feature that has no dedicated page." "Your Spanish site is missing four pages that exist in English." This converts a maintenance chore into a value-add the customer didn't know they needed. Their own teams typically cannot find these issues at scale; the bot can.
Compounding answers. When a question gets answered well, the answer should be filed back into the knowledge base as a derived page — with proper provenance to the sources it was synthesized from. Next time someone asks a similar question, the bot retrieves the prior answer instead of re-synthesizing. Quality compounds; cost goes down.
Typed entities for business contexts. Customer knowledge bases are not free-form research notes; they have a natural ontology — Product, Plan, Pricing, Policy, FAQ, Article, Customer Segment. Encoding these types and their relationships gives the bot the kind of structural understanding that pure vector search cannot. Combined with hybrid retrieval, this is a meaningful accuracy upgrade.
A human-readable wiki view of every knowledge base. Today, what's stored in our index is invisible to customers — they see chat logs and a settings panel. Imagine instead an Obsidian-style browsable view of their knowledge base: every entity as a page, every relationship as a link, the graph view showing the shape of their content. For internal-facing chatbots especially, this transforms the product from "a chat box" into "a living knowledge artifact." It's also a moat: switching costs go up dramatically when the customer's compiled wiki is part of what they're paying for.
Confidence scoring and HITL on contradictions. When new content contradicts existing content, don't silently overwrite. Surface it. Let the customer decide. This is the difference between a chatbot people trust enough to ship to production and one they don't.
The bigger point is this. The LLM Wiki movement is a signal that the field is starting to move past retrieval-augmented generation and toward something closer to compiled-knowledge generation. The shape this takes for individual researchers (a folder of Markdown + an LLM agent) won't be the shape it takes for businesses with thousands of sources, multilingual content, frequently changing data, and compliance requirements. But the underlying principles — compile once, accumulate, cite sources, lint for consistency, make the knowledge artifact a first-class deliverable — apply just as powerfully.
That's the direction we're building in. If you're building or running a chatbot on top of a non-trivial knowledge base, we'd love to talk to you about what we're cooking. And if you want to read the original idea — the gist that started all of this — it's right here, and it remains worth your fifteen minutes.
Want to try a knowledge-base chatbot that actually knows your business? Start free with Denser.ai or explore Denser Retriever for the API.