How A Retriever for RAG Can Transform Your Data Strategy

The Retrieval Augmented Generation (RAG) model is making a big impact in business technology thanks to its core component, the retriever. This tool changes how AI systems operate by pulling relevant information from large databases when answering queries.
This is a major upgrade from older systems that rely only on pre-stored data, making the retriever essential for businesses that need quick and accurate information.
In this article, we'll explore why it's important to choose the best retriever for RAG and how this technology can benefit your business. The right retriever can make data handling more efficient and improve response accuracy.
What is Retrieval Augmented Generation (RAG)?#
Retrieval-augmented generation is a cutting-edge AI method that improves large language models (LLM) by using external knowledge sources in their generation process.
RAG was developed to overcome the limitations inherent in traditional language models, which generate accurate responses solely based on the input received and the training data.
Traditional models perform well in many situations, but they can falter in scenarios that demand precise, factual knowledge or the ability to reference various information sources.
How Does RAG Work?#
Unlike traditional LLMs that only work with the info they've been trained on, RAG models can churn out responses that are accurate and relevant to the context.
Here's a simplified explanation of how RAG works:
RAG combines a pre-trained system designed to locate relevant information, known as the retriever, with another system that's adept at generating text, called the generator.
When you ask a question or input a query, the retriever uses a retrieval method called "Maximum Inner Product Search (MIPS)" to quickly identify the most relevant data or documents.
This selected information is then passed on to the generator, which crafts the detailed response. One of the neat features of this process is that it includes citations, allowing users to check the sources themselves and explore the information further if they wish.
How RAG Improves Large Language Models#
The integration of RAG into LLMs centers around two critical components: the retriever and the generator. Here's how each part contributes to the process:
The Retriever#
The retriever's job is to scour through a vast array of documents or databases to find information that matches the input query. This component determines the relevance and quality of the information that will be used to generate the final response.
It acts like a highly specialized search engine, pinpointing the most pertinent documents based on the query specifics.
The Generator#
Once the retriever has identified and fetched the most relevant documents, the generator takes over. It uses the content of these retrieved documents, along with the original query, to craft a comprehensive and contextually appropriate response.
The generator synthesizes the new information with the pre-existing knowledge embedded in the LLM, allowing for responses that are not only accurate but also richly detailed and deeply informed.
Use Cases of Retrievers for RAG#
Retrievers for RAG make it easier and faster to handle large amounts of information across different industries. Here's a look at how these powerful tools are being used in several key areas.
Legal Document Review#
Law firms and legal departments deal with huge piles of documents every day. Retrievers help by quickly retrieving documents and parts of texts needed.
They can search through legal documents using specific keywords or by understanding the context.
Customer Support Improvements#
Retrievers are also a big help in customer service. They power chatbots that can pull up the right answers from a large pool of information in seconds.
This means customers get better, clearer answers quickly, which makes them happier and improves their overall experience.
Semantic Search Engines#
Semantic search engines are designed to understand what people are looking for when they type a query. Retrievers help these search engines by figuring out the context of queries, which allows them to provide more accurate and contextually relevant search results.
Semantic understanding is especially helpful in areas like academic research, online shopping, and finding content online.
Rapid Prototyping Across Various Industries#
This is for developers working in different fields, such as engineering, data science, marketing, and content creation.
Retrievers can speed up the development of new projects. They make it easy to set up and start testing new ideas quickly, which saves time and helps bring new products and services to market faster.
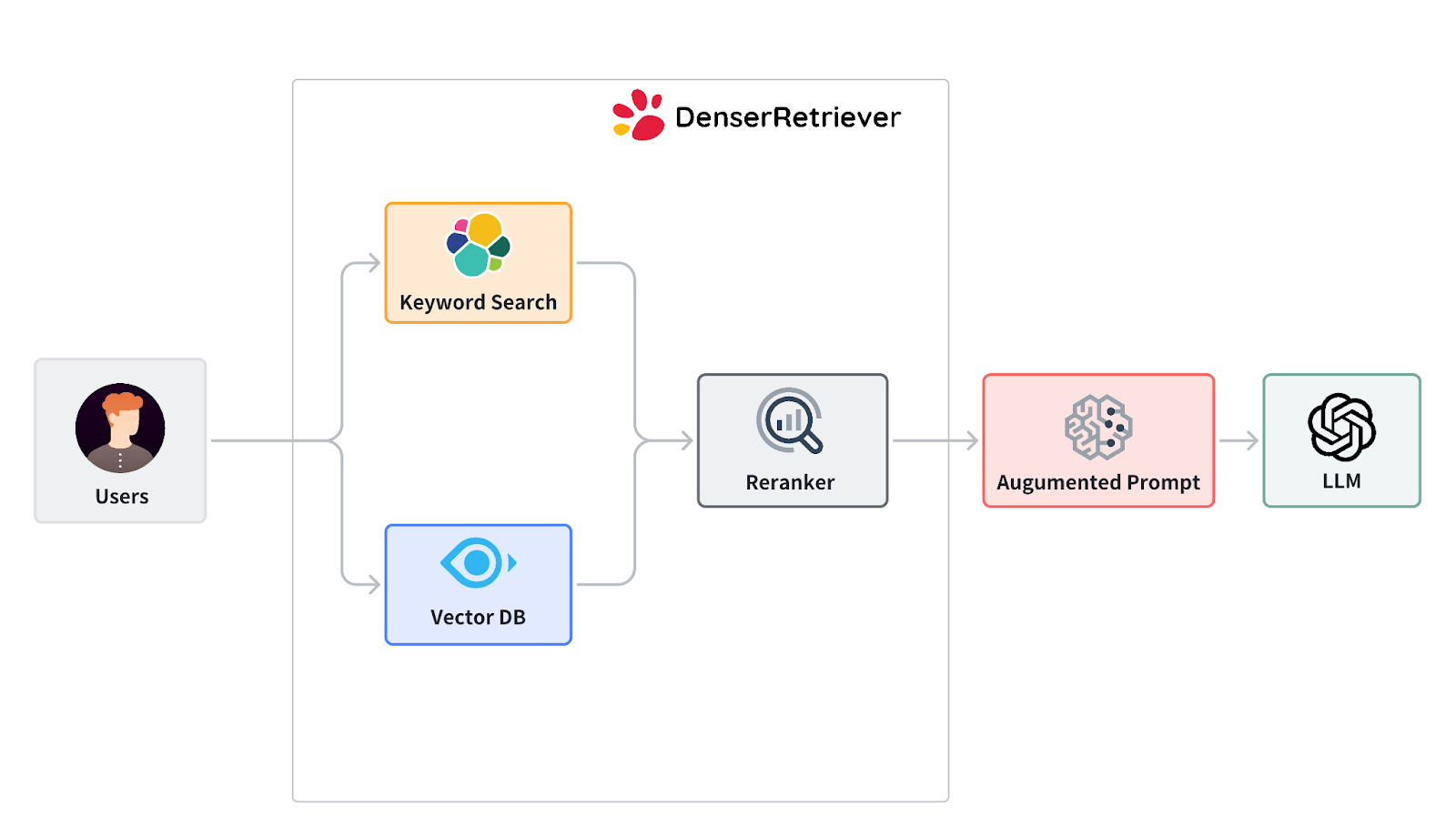
How the Denser Retriever Project Illustrates the Impact of RAG#
The Denser Retriever project stands out as a key example of how RAG can be used to improve search capabilities. This open-source project merges several search technologies into one unified platform.
It uses gradient boosting techniques, specifically XGBoost, to seamlessly integrate keyword-based searches with vector databases and machine learning rankers. The outcome is a search system that delivers significantly higher accuracy than traditional vector search methods.
In practical testing, such as on the widely recognized MSMARCO benchmark dataset, the Denser Retriever has shown exceptional performance. It achieved a relative NDCG@10 gain of 13.07% over the top-performing vector search baseline. For benchmarks comparing open-source embedding models with paid alternatives like Anthropic and Cohere, our experiments show free models can match or exceed paid options.
If you are interested in learning more about the project or contributing to its development, resources are available, including:
- GitHub Repository: Denser Retriever Repo
- Documentation: Denser Retriever Documentation
Key Benefits of Integrating Denser Retriever#
Adopting Denser Retriever can improve your operations, offering a range of benefits tailored to meet various operational and technical demands:
Open Source Benefits#
Denser Retriever is an open-source solution, which means you get complete visibility into its codebase.
This openness invites a continuous stream of improvements and updates from a global community of developers to ensure the tool stays innovative and up-to-date.
Ready for the Real World#
Denser Retriever is built to be ready right out of the box for production environments. It's designed to be stable, robust, and reliable—exactly what you need for real-world applications.
This reduces the time and resources you'd typically spend on development and troubleshooting, making your life a lot easier.
Precision at Its Best#
The tool is renowned for its top-notch accuracy, which boosts the precision of AI-driven applications.
This means you can rely on Denser Retriever for dependable results that help drive better decision-making and lead to more successful outcomes, no matter your industry.
Scales with Your Business#
Whether your data is growing or your user base is expanding, Denser Retriever is up to the task.
It's designed to handle varying loads with ease, making it a perfect fit for businesses of all sizes looking to scale without stress.
Flexible Across Industries#
Denser Retriever's adaptability makes it a valuable asset in various settings.
It's customizable to meet the unique needs of your specific projects, whether that's diving deep into data analysis, boosting customer service, or conducting complex academic research.
Steps for Setting Up a Retriever for RAG#
This guide walks you through installing the Denser Retriever package, setting up necessary tools like Elasticsearch and Milvus, and verifying that everything is functioning correctly.
Initial Setup#
First, you'll need to install the Denser Retriever. We manage this package using Poetry. Follow these steps to get started:
Clone the Denser Retriever repository to your local machine:
git clone https://github.com/denser-org/denser-retriever
cd denser-retriever
make install
You can find more detailed instructions in the DEVELOPMENT documentation provided within the repo.
Installing Required Tools#
To effectively run the Denser Retriever, you'll need Elasticsearch and Milvus, which support keyword and vector database search, respectively:
- Requirements: Ensure you have Docker and Docker Compose installed on your machine. These tools are included in Docker Desktop for both Mac and Windows users.
- Setup Elasticsearch and Milvus:
- Download the docker-compose.dev.yml file and save it as docker-compose.yml. You can do this manually or by using the following command:
wget https://raw.githubusercontent.com/denser-org/denser-retriever/main/docker-compose.dev.yml \
-O docker-compose.yml
- Start the services using Docker Compose with the command:
docker compose up -d
Verifying the Installation#
Optionally, after setting up the services, you can check that Milvus is installed and running correctly with this command:
poetry run python -m pytest tests/test_retriever_milvus.py
Make Data Retrieval Effortless with Denser Retriever#
Discover how Denser Retriever can transform your approach to data handling.
Get started in minutes with an easy Docker Compose setup. Our self-hosted solution is perfect for enterprise-level deployment and is tailored to simplify and improve your data retrieval processes.
Explore the Denser Retriever platform to see how it can transform your data retrieval.
Deploy Denser Retriever now, or contact us to learn more about how our advanced solutions can revolutionize your data management!
FAQs About Retriever for RAG#
Can fine-tuning be applied to both the query and the retrieval components?#
Yes, fine-tuning can be applied to both the query processing and the retrieval components of the RAG system. For the query component, fine-tuning helps the system better understand and interpret user inputs.
For the retrieval component, it improves the model's ability to select the most relevant documents based on those refined queries. Optimizing both components ensures that the entire system works more efficiently together.
What impact does the size of the data source have on an RAG Retriever's performance?#
The size of the data source can significantly affect the performance of an RAG Retriever. Larger datasets may provide more comprehensive information but can also increase the retrieval time and computational requirements.
It's important to optimize data structures and use efficient indexing methods to balance the depth of data with retrieval speed.
Can RAG Retrievers integrate with existing enterprise systems?#
Yes, RAG Retrievers can be integrated with existing enterprise systems such as customer relationship management (CRM) tools, enterprise resource planning (ERP) systems, and other data management platforms.
This integration allows for seamless data retrieval processes that leverage both structured and unstructured data from enterprise operations.