Claude vs ChatGPT vs Gemini: The 2026 Comparison for Builders & Businesses


Claude, ChatGPT, and Gemini are the three frontier AI model families shaping how businesses build products, automate workflows, and serve customers in 2026. Each has evolved rapidly — Claude is now on Opus 4.8, ChatGPT runs GPT-5.5, and Gemini has reached 3.1 Pro — and each excels in different areas. There is no single winner.
If you need the short answer: Claude is best for coding and nuanced writing, ChatGPT is the best all-purpose default, and Gemini leads on context size, multimodal input, and value pricing. But the real decision depends on your use case — especially if you're building a RAG-powered chatbot or knowledge base assistant, where retrieval architecture matters more than raw model capability.
This guide compares all three across features, benchmarks, pricing, use cases, and — critically — which model works best when paired with retrieval-augmented generation for business deployment.
Key Takeaways#
- No single model dominates every task. Claude leads coding and writing benchmarks; GPT-5.5 is state-of-the-art across 14 benchmarks; Gemini wins on context size, multimodal, and abstract reasoning.
- Context windows have converged at 1M+ tokens, but Gemini's 2M standard window and native multimodal processing give it an edge for large-document and video/audio workloads.
- Pricing varies dramatically. Claude Opus costs $5/$25 per million tokens; GPT-5 is $1.25/$10; Gemini 3 Flash is $0.50/$3 — a 50x spread on output pricing.
- For RAG and chatbot deployment, the model is only half the equation. Retrieval architecture (hybrid search + reranking + citations) matters as much as which LLM you choose.
- GPT-5.4 mini is the most deployed model in customer support chatbots in 2026, but accuracy depends on grounding, not model size.
Current Models and Versions (As of Mid-2026)#
The model landscape has moved extremely fast. Here's where each family stands today.
Anthropic Claude#
| Model | Released | Key Highlights |
|---|---|---|
| Claude Opus 4.8 | May 28, 2026 | "More effective collaborator" with sharper judgment; same pricing as 4.7 |
| Claude Opus 4.7 | April 16, 2026 | Most intelligent publicly available model; knowledge cutoff January 2026 |
| Claude Opus 4.6 | February 5, 2026 | First Opus with 1M-token context window (beta); 76% on MRCR v2 8-needle test |
| Claude Sonnet 4.6 | February 17, 2026 | Default for free and Pro users; full upgrade across coding, reasoning, planning |
| Claude Haiku 4.5 | October 2025 | Performance comparable to Sonnet 4 at ~1/3 the cost ($1/M input) |
OpenAI GPT#
| Model | Released | Key Highlights |
|---|---|---|
| GPT-5.5 ("Spud") | April 23, 2026 | Most advanced model; state-of-the-art across 14 benchmarks; up to 1M context |
| GPT-5.5 Instant | May 5, 2026 | New default ChatGPT model; 52.5% fewer hallucinated claims than GPT-5.3 |
| GPT-5.2 | December 11, 2025 | "Most capable model series for professional knowledge work" |
| GPT-5 | August 7, 2025 | Unified system replacing GPT-4o and o3; hallucinates ~80% less than GPT-4o; free for all users |
Google Gemini#
| Model | Released | Key Highlights |
|---|---|---|
| Gemini 3.1 Pro | February 19, 2026 | 77.1% on ARC-AGI-2; upgraded reasoning; available in Gemini app, Vertex AI |
| Gemini 3 Pro | November 18, 2025 | LMArena 1501 Elo; state-of-the-art multimodal and agentic coding |
| Gemini 3 Flash | December 2025 | "Frontier intelligence built for speed"; outperforms Gemini 2.5 Pro on benchmarks |
| Gemini 2.5 Pro | March 2025 | 1M token context; "Deep Think" chain-of-thought mode |
Feature Comparison#

Context Window Sizes#
| Model | Context Window | Notes |
|---|---|---|
| Claude Opus 4.6+ | 200K standard, 1M beta | 1M available for API tier 4+ users |
| Claude Sonnet 4.6 | 200K standard, 1M beta | 1M in beta |
| GPT-5 | 200K–400K | Expanded to 1M with GPT-5.5 |
| Gemini 2.5 Pro/Flash | 1M standard | Native, not beta |
| Gemini 3.1 Pro | 1M–2M | Largest standard context available |
Key insight: Gemini has the largest standard context (1M–2M), Claude offers 1M in beta, and GPT-5.5 expanded to 1M. Gemini's 2M window is 5x larger than Copilot's 400K. However, Gemini's reliable retrieval degrades in the final 200K tokens, and requests over 200K incur a 2x pricing surcharge.
Multimodal Capabilities#
| Capability | Claude | ChatGPT (GPT-5) | Gemini |
|---|---|---|---|
| Text | ✅ | ✅ | ✅ |
| Image input | ✅ | ✅ | ✅ |
| Video input | ❌ | ❌ | ✅ (native) |
| Audio input | ✅ (TTS) | ✅ | ✅ (native) |
| Image generation | ❌ (via tools) | ✅ | ✅ |
| Music generation | ❌ | ❌ | ✅ (Lyria 3) |
Gemini is natively multimodal — trained from the ground up on text, image, audio, and video. GPT-5 is multimodal but lacks native video/audio. Claude supports image input but has no native video or audio capabilities.
Tool Use and Function Calling#
| Capability | Leader | Score |
|---|---|---|
| Multi-turn tool calling | GPT-5.2 | 98.7% TAU2-Bench |
| Cross-MCP tool coordination | Gemini 3.1 Pro | 69.2% MCP-Atlas |
| Professional agentic tasks | Gemini 3.1 Pro | 33.5% APEX-Agents |
| Long-horizon autonomous tool use | Claude Opus 4.6 | 72.7% OSWorld |
The Model Context Protocol (MCP) has become the standard for connecting AI agents to external tools. As of April 2026, 10 major AI agents support custom remote MCP servers with native OAuth 2.1.
Benchmark Performance#
GPT-5.5: State-of-the-Art Across 14 Benchmarks#
When GPT-5.5 launched in April 2026, it achieved state-of-the-art on 14 benchmarks (vs. 4 for Claude Opus 4.7 and 2 for Gemini 3.1 Pro). It dominates in agentic computer use, economic knowledge work (GDPval), specialized cybersecurity (CyberGym), and complex mathematics (Frontier Math).
What the Benchmarks Mean in Practice#
Benchmarks measure specific capabilities under controlled conditions, but real-world performance depends on how you use the model. A few observations:
- Claude leads on coding and writing tasks — for example, WebDev Arena 82.1%. If you're building software or generating long-form content, Claude is the strongest choice.
- GPT-5.5 leads on breadth and structured reasoning — state-of-the-art across 14 benchmarks, best multi-turn tool calling (98.7% TAU2-Bench), and best computer use (75% OSWorld, surpassing the human expert baseline).
- Gemini leads on multimodal and abstract reasoning — 77.1% on ARC-AGI-2, 72.2% on MMMU-Pro (multimodal), and the largest context window. For tasks involving video, audio, or massive document sets, Gemini has no equal.
Pricing Comparison#
API Pricing (per 1M tokens, USD)#
| Provider | Model | Input | Output | Context |
|---|---|---|---|---|
| Anthropic | Claude Opus 4.6/4.7/4.8 | $5.00 | $25.00 | 200K/1M beta |
| Anthropic | Claude Sonnet 4.6 | $3.00 | $15.00 | 200K/1M beta |
| Anthropic | Claude Haiku 4.5 | $1.00 | $5.00 | 200K |
| OpenAI | GPT-5 | $1.25 | $10.00 | 200K–400K |
| OpenAI | GPT-5 Mini | $0.25 | $2.00 | 32K |
| Gemini 3.1 Pro | $2.00 | $12.00 | 2M | |
| Gemini 3 Flash | $0.50 | $3.00 | 2M | |
| Gemini 2.5 Flash-Lite | $0.10 | $0.40 | 1M |
Critical cost considerations:
- Reasoning token overhead: Actual cost for reasoning models is 3–9x the headline output price due to internal "thinking" tokens that aren't shown in the response but are billed.
- Cached input pricing: GPT-5 cached $0.125/M; Claude cache hit $0.50/M; Gemini context $0.03/M — caching can dramatically reduce costs for repeated queries.
- Gemini surcharge: Requests over 200K tokens incur 2x pricing.
Consumer Subscription Pricing (2026)#
| Provider | Tier | Price | Key Features |
|---|---|---|---|
| ChatGPT | Free | $0 | Limited model access |
| ChatGPT | Plus | $20/mo | Full model access |
| ChatGPT | Pro | $100–$200/mo | Unlimited advanced reasoning |
| Claude | Free | $0 | Daily usage caps |
| Claude | Pro | $20/mo | ~100–150 messages per 5-hour period |
| Claude | Max (5×) | $100/mo | 5× message limits |
| Claude | Max (20×) | $200/mo | 20× message limits, priority |
| Google AI | Free | $0 | Basic Gemini access |
| Google AI | Pro | $19.99/mo | Full Gemini access |
| Google AI | Ultra | $99.99/mo | Highest model access (cut from $249.99 at I/O 2026) |
Strengths and Weaknesses#
Claude (Anthropic)#
Strengths:
- Best for nuanced, long-form writing — often described as a "surgeon's scalpel" for content
- Leads coding benchmarks (e.g., WebDev Arena 82.1%)
- Best long-horizon autonomous tool use (72.7% OSWorld)
- Strong safety and ethical alignment focus
- Excellent document reasoning and analysis
- Claude Code is a powerful autonomous coding agent (hit $1B ARR)
- Agent Skills are now an open standard, portable across platforms
Weaknesses:
- Most expensive flagship model ($5/$25 per 1M tokens)
- Smaller standard context window (200K; 1M only in beta)
- No native video or audio input
- No built-in image generation
- Usage limits can be restrictive for power users
ChatGPT / GPT (OpenAI)#
Strengths:
- Best all-purpose default — the "Swiss army knife" of AI models
- GPT-5.5 is state-of-the-art across 14 benchmarks
- Strongest structured reasoning and computer use (75% OSWorld)
- Best multi-turn tool calling (98.7% TAU2-Bench)
- Free tier available (GPT-5 free for all users)
- Most comprehensive memory and personalization features
- Widest ecosystem and integrations
- GPT-5.5 Instant has 52.5% fewer hallucinated claims than its predecessor
Weaknesses:
- Smaller context window than Gemini (200K–400K standard, 1M with 5.5)
- No native video input
- Higher Pro tier cost ($200/mo)
- Fewer built-in productivity features than some competitors in certain categories
Gemini (Google)#
Strengths:
- Largest context window (1M–2M tokens standard)
- Best native multimodal capabilities (text, image, audio, video)
- Best abstract reasoning (ARC-AGI-2: 77.1%)
- Best multimodal comprehension (MMMU-Pro: 72.2%)
- Best value pricing (Flash-Lite at $0.10/$0.40 per 1M tokens)
- Free tier with generous limits
- Deep Research agent for long-running synthesis tasks
- Strong Google ecosystem integration (Workspace, Search, Android, Chrome)
- Lyria 3 AI music generation and robotics applications
Weaknesses:
- Weaker on coding benchmarks (SWE-bench Verified: 68.3% for 3.1 Pro)
- Gemini 3.0 had stability issues and higher hallucination rates vs. 2.5 Pro
- Less nuanced writing than Claude
- Google ecosystem lock-in for full feature access
- Tiered pricing surcharge for context over 200K tokens
Best Use Cases for Each Model#
Claude — Best For:#
- Complex coding and software engineering — especially with Claude Code for autonomous development
- Long-form writing with nuanced tone and careful analysis
- Frontend code generation — produces the cleanest, most idiomatic code
- Autonomous agent workflows requiring long-horizon planning
- Safety-critical applications requiring ethical alignment
- Enterprise knowledge work — Deloitte's massive deployment, legal tools with 12 plugins
ChatGPT / GPT — Best For:#
- All-purpose general tasks — if you're not sure which model to use, start here
- Research, writing, and agent-style workflows across diverse domains
- Structured reasoning and math — state-of-the-art across 14 benchmarks
- Computer use and agentic tasks — OSWorld leader
- Multi-turn tool calling and sequential API workflows
- Personalized assistance — memory, connected accounts, custom instructions
- Enterprise deployment — most widely deployed model in support chatbots
Gemini — Best For:#
- Large document processing — 1M–2M context window handles entire codebases
- Multimodal tasks — video, audio, and image understanding in one model
- Research and analysis — Deep Research agent for long-running synthesis
- Cost-sensitive high-volume deployments — Flash and Flash-Lite tiers
- Google ecosystem workflows — Workspace, Search, Android, Chrome integration
- Scientific benchmarks and abstract reasoning — ARC-AGI-2 leader
Which Model Is Best for RAG and Chatbot Deployment?#
This is the question that matters most for businesses building customer-facing AI. And the answer is more nuanced than "pick the best model."
The RAG Reality: Retrieval Architecture > Model Choice#
For retrieval-augmented generation, the model is only one component. The retrieval pipeline — how you find the right information in your knowledge base and feed it to the model — has a bigger impact on answer accuracy than which frontier model you use.
Gemini excels for RAG with large document bases due to its 1M–2M context window — you can ingest entire codebases or dozens of documents in a single call.
Claude excels for RAG requiring high-quality synthesis and nuanced analysis of retrieved documents — its writing strength translates directly to better answer composition.
GPT-5 excels for RAG requiring tool calling and multi-step retrieval workflows — its 98.7% TAU2-Bench score means it can reliably orchestrate multiple retrieval steps.
Best LLM for Customer Service Chatbots (2026)#
According to industry analysis, GPT-5.4 mini is the most deployed model in support chatbots in 2026 — offering the best balance of language quality, low latency, and cost. Claude Sonnet 4.6 is strong for quality-critical enterprise chatbots, and Gemini 3.1 Flash is best for high-volume, low-latency needs.
The Problem With Model-Only Thinking#
Here's what most comparison articles won't tell you: choosing the best LLM for your chatbot is necessary but not sufficient. Even the best model will hallucinate 15–27% of the time if it's generating answers from its training data rather than from your verified documents.
The real differentiator in production chatbots is the retrieval architecture:
- Standard vector search only — finds semantically similar content but misses exact keyword matches (part numbers, policy sections, names)
- Hybrid retrieval (keyword + vector + ML reranking) — combines exact matching with semantic understanding, then uses a machine learning model to rerank results for maximum relevance
- Source citations — every answer links back to the exact passage it came from, so users and businesses can verify accuracy
How Denser.ai Approaches This Differently#
Denser.ai is built on a RAG architecture powered by the Denser Retriever — a hybrid retrieval engine that combines keyword search, vector semantic search, and ML reranking in a single pipeline.
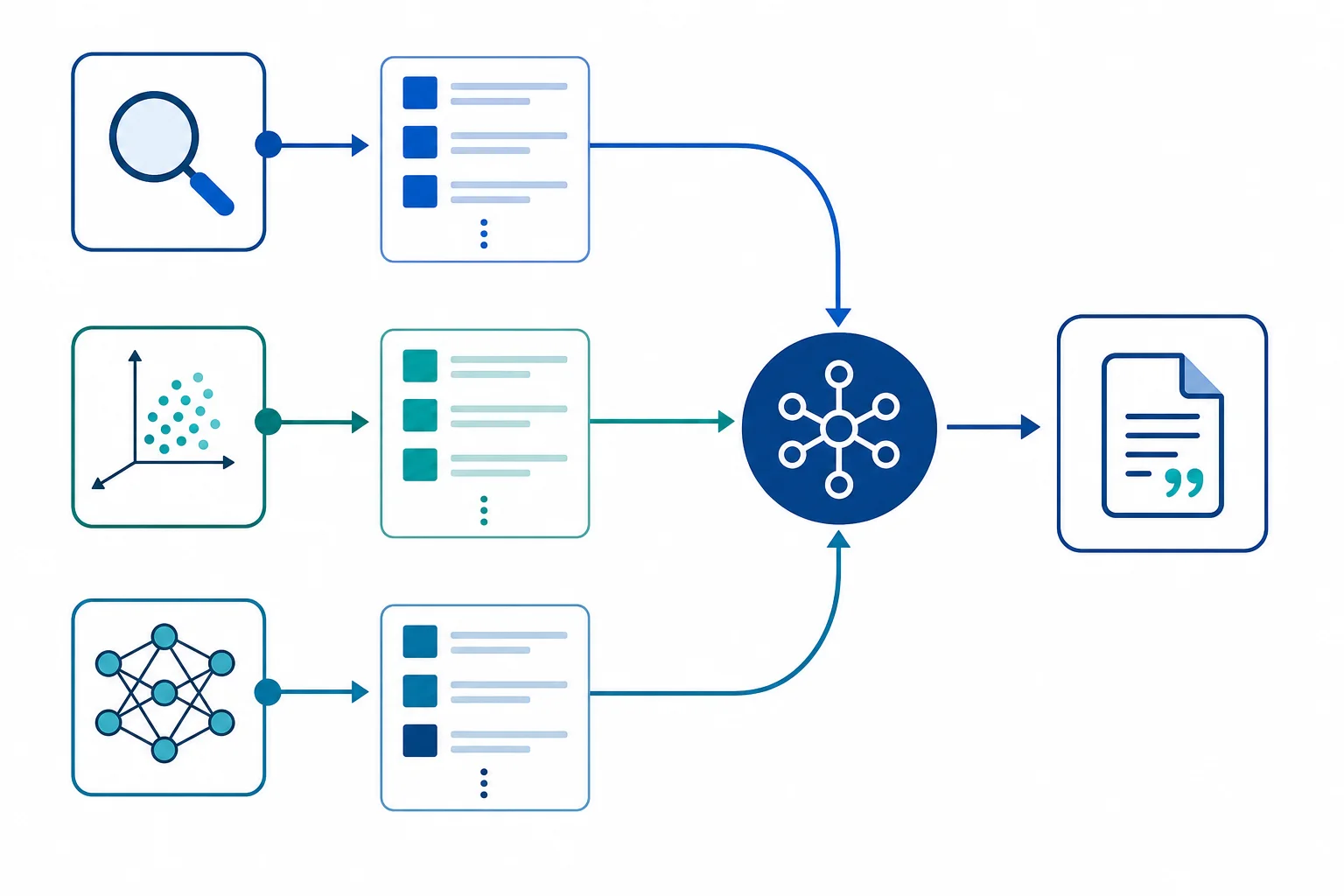
This matters because different queries benefit from different retrieval strategies:
- "What's our refund policy?" → semantic search finds the concept even if the exact word "refund" isn't in the document
- "Find section 3.2.2" → keyword search nails the exact reference that semantic search might miss
- "Which of these 50 documents is most relevant?" → ML reranking re-scores all candidates for the best ordering
Every answer from a Denser-powered chatbot includes a source citation linking to the exact page and passage it came from. If the answer isn't in your connected documents, Denser says so rather than guessing.
This is the architectural choice that drops hallucination rates from 15–27% to under 2%. It's also what differentiates Denser from platforms that use a single retrieval method or generate answers without citations — see how it compares to other chatbots.
Denser's KB Health Feature#
Beyond retrieval, Denser includes KB Health — a feature that scans every connected document for conflicting facts and surfaces them with a confidence score. If your pricing-v1.pdf says something different from pricing-v2.pdf, you'll know before a customer does.
This is particularly relevant when comparing LLMs: no matter which model you choose, if your source documents contain contradictions, the model will surface inconsistent answers. KB Health solves this at the source.
No-Code Deployment#
While choosing between Claude, ChatGPT, and Gemini typically requires API integration and engineering work, Denser handles the entire pipeline — retrieval, model selection, citations, and deployment — through a no-code interface. You paste your website URL or upload documents, and Denser crawls, indexes, and deploys a branded chat widget in under 5 minutes. It scales to 100,000+ pages with no loss in answer accuracy and supports 80+ languages with automatic detection.
Deploy a cited-answer chatbot in 5 minutes →
Recent News and Updates (2025–2026)#
Anthropic / Claude#
- May 28, 2026: Claude Opus 4.8 released — "more effective collaborator" with sharper judgment
- May 2026: Code with Claude developer conference — SpaceX deal for Memphis data center compute; doubled Claude Code usage limits
- 2026: Anthropic raised $30 billion (Series G) at a $380 billion post-money valuation
- May 14, 2026: 12 new AI legal tools unveiled for corporate, regulatory, and employment law
- April 2026: Claude Opus 4.7 released; Claude Mythos announced (deemed too dangerous for public release)
- October 2025: Biggest enterprise deployment ever with Deloitte; $13 billion funding round at $183 billion valuation
- Late 2025: Claude Code hit $1B annualized revenue run rate
OpenAI / GPT#
- May 15, 2026: ChatGPT Finance Dashboard launched for Pro users — connects to 12,000+ banks via Plaid
- May 5, 2026: GPT-5.5 Instant released as new default ChatGPT model; 52.5% fewer hallucinated claims
- April 23, 2026: GPT-5.5 ("Spud") released; state-of-the-art across 14 benchmarks; Nvidia says new chips slash cost up to 35x per token
- August 7, 2025: GPT-5 launched; unified system replacing GPT-4o and o3; free for all users; hallucinates ~80% less than GPT-4o
Google / Gemini#
- February 2026: Gemini 3.1 Pro released; Lyria 3 AI music model deployed with SynthID watermarking
- January 2026: Boston Dynamics + Google DeepMind partnership at CES 2026; Gemini Robotics integrated into Atlas humanoid robot
- November 2025: Gemini 3 launched; LMArena 1501 Elo; available across Google Search, Gemini app, Vertex AI
- Google I/O 2026: Google AI Ultra cut to $99.99/month (from $249.99)
The Verdict: Which Should You Choose?#
For Coding#
Choose Claude. It leads every coding benchmark that matters — Arena code Elo, WebDev Arena, Aider Polyglot, LiveCodeBench. Claude Code is the premier autonomous coding agent and has hit $1B ARR. If you're a developer or engineering team, Claude is the strongest choice for complex, sustained software engineering.
For General-Purpose Use#
Choose ChatGPT. GPT-5.5 is state-of-the-art across 14 benchmarks, has the best tool calling, the widest ecosystem, and a free tier. If you want one AI assistant that can handle anything you throw at it — writing, research, analysis, image generation, code — ChatGPT is the safest default.
For Large Documents and Multimodal#
Choose Gemini. The 1M–2M context window handles entire codebases and document libraries. Native video and audio understanding is unmatched. And the Flash-Lite tier at $0.10/$0.40 per 1M tokens is the best value in the market for high-volume workloads.
For RAG-Powered Business Chatbots#
Choose the right retrieval architecture, not just the right model. GPT-5.4 mini is the most deployed model in support chatbots, but the accuracy of your chatbot depends far more on how you retrieve and ground information than on which LLM you pick. A platform like Denser.ai that combines hybrid retrieval (keyword + vector + ML reranking) with mandatory source citations will outperform any model-only approach — because it eliminates the hallucination problem at the architectural level rather than trying to solve it with a bigger model.
Frequently Asked Questions#
Which is better: Claude, ChatGPT, or Gemini?#
There is no single best model. Claude leads coding and writing benchmarks; ChatGPT (GPT-5.5) is state-of-the-art across 14 benchmarks and is the best all-purpose default; Gemini leads on context size (1M–2M tokens), native multimodal capabilities, and value pricing. Your choice should depend on your specific use case.
Is Claude better than ChatGPT for coding?#
Yes, in most benchmarks. Claude Opus 4.6 leads on WebDev Arena (82.1%), Aider Polyglot (68.4%), LiveCodeBench (71.2%), and Arena code Elo (1548). Claude Code is also the most widely used autonomous coding agent, hitting $1B ARR. However, GPT-5.5 is state-of-the-art across 14 benchmarks overall and excels at multi-turn tool calling in coding workflows.
Which AI model has the largest context window?#
Google Gemini 3.1 Pro has the largest standard context window at 1M–2M tokens. Claude offers 1M tokens in beta (200K standard), and GPT-5.5 expanded to 1M (200K–400K standard for earlier GPT-5 versions). Gemini's large context is particularly useful for processing entire codebases or large document collections.
Which model is best for building a chatbot?#
For customer service chatbots, GPT-5.4 mini is the most deployed model in 2026 due to its balance of quality, latency, and cost. However, the model choice matters less than the retrieval architecture. Chatbots that ground every answer in retrieved source material with citations (like Denser.ai) achieve hallucination rates under 2%, compared to 15–27% for ungrounded models.
How much does each AI model cost?#
API pricing per 1M tokens: Claude Opus costs $5 input / $25 output; GPT-5 costs $1.25 / $10; Gemini 3 Flash costs $0.50 / $3; and Gemini 2.5 Flash-Lite costs $0.10 / $0.40. Consumer subscriptions range from $20/month (ChatGPT Plus, Claude Pro, Google AI Pro) to $200/month (ChatGPT Pro, Claude Max 20×). Note that reasoning models incur 3–9x the headline cost due to thinking tokens.
Which model hallucinates the least?#
GPT-5.5 Instant has 52.5% fewer hallucinated claims than its predecessor. GPT-5 overall hallucinates ~80% less than GPT-4o. However, the biggest reduction in hallucinations comes not from the model but from the retrieval architecture — grounding answers in cited source material drops hallucination rates from 15–27% to 0.7–1.5%.
Start Building With Cited Answers#
The frontier model war between Claude, ChatGPT, and Gemini will continue — each will leapfrog the others with every release. But for businesses building customer-facing AI, the model is table stakes. The real competitive advantage is in how you retrieve, ground, and cite information.
Denser.ai combines hybrid retrieval (keyword + vector + ML reranking) with mandatory source citations and contradiction detection — deployed through a no-code interface in under 5 minutes. Whether you ultimately pair it with Claude, GPT, or Gemini, the retrieval architecture is what ensures your chatbot gives accurate, trustworthy answers every time.
Build your cited-answer chatbot →