Elasticsearch Alternatives in 2026: Architecture Decision Guide for Developer Teams

Elasticsearch is a mature search engine and remains the industry benchmark at large scale.
But search itself has shifted over the past two years --- semantic retrieval has moved from a nice-to-have to a baseline requirement, AI applications increasingly depend on vector search, and lightweight alternatives have made deliberate trade-offs on developer experience and operational cost.
Given these shifts, which search engine should you choose? There are more good answers now than there used to be.
Below are six alternatives worth shortlisting, with notes on which kind of team and use case each one fits.

Six Alternatives at a Glance#
Tool Search Type Semantic / Vector Ops Complexity Deployment
Denser Retriever Keyword + Vector + Re-rank Native three-layer pipeline Low, managed SaaS API / SaaS
Typesense Keyword + Vector Built-in vector search Low, simple ops Self-host / Cloud
Meilisearch Keyword + Vector Built-in hybrid search Very low, easy to run Self-host / Cloud
OpenSearch Keyword + Vector (k-NN) Plugin-based High, similar to ES Self-host / AWS
Pinecone Vector only Purpose-built vector DB Low, managed SaaS SaaS
Weaviate Vector + Keyword hybrid Native multimodal Medium, self-host or Cloud Self-host / Cloud#
Denser Retriever: Managed SaaS with Three-Layer Retrieval#
The most common scenario where Elasticsearch starts to feel heavy is enterprise internal knowledge search --- documentation, runbooks, HR policies, product specs spread across heterogeneous sources.
The bar for search quality is high, but the team doesn't have a dedicated search platform engineer.
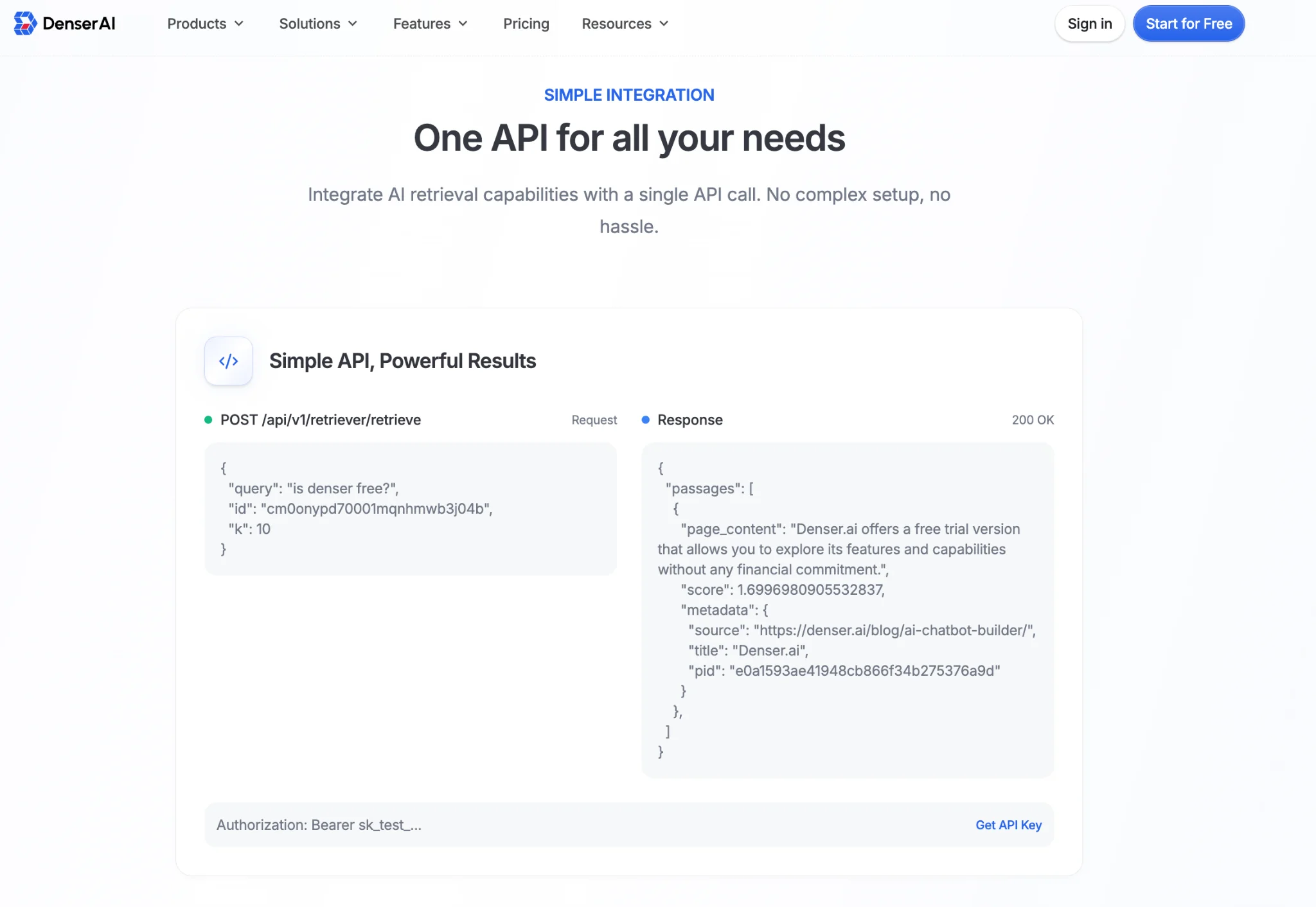
Denser Retriever runs keyword and vector retrieval as a unified three-layer pipeline rather than two separate systems that each need tuning.
The keyword layer handles exact term matching, the vector layer covers synonyms and intent-based queries, and the re-ranking layer picks the most contextually relevant result from the combined candidate set.
Multi-source indexing is native --- websites, PDFs, and SQL/NoSQL databases all live in the same project and return unified results in every query.
Responses include paragraph-level source citations, which matters for enterprise scenarios where answers need to be verifiable.
On the deployment side, Denser Retriever is a fully managed SaaS --- no clusters to provision, no shard allocation, heap tuning, or index lifecycle management.
Integration follows a standard REST pattern: create a project in the dashboard, connect your data sources, and query via API.
For compliance and infrastructure, Denser Retriever is SOC 2 Type II certified, hosted on US infrastructure, and supports automatic language detection across 80+ languages.
For teams operating across regions and languages, that combination removes a layer of localization work.
Overall, Denser Retriever is built for teams that want semantic search, source citations, and fast deployment without taking on cluster operations.
Organizations in the 30-to-500-person range that need to roll out search quickly and care about answer verifiability typically find it on their shortlist.
Typesense: Developer-Friendly Structured Search#
Typesense is an open-source search engine designed for developer ergonomics. A single binary, minimal configuration, a clean REST API, built-in typo tolerance, and vector search make it a low-friction option for teams that want search quality without Elasticsearch's operational weight.
The practical scope is structured data --- product catalogs, documentation sites, and applications where the data model is well-defined.
It's not the right fit for heterogeneous, unstructured enterprise knowledge retrieval. Typesense Cloud offers a managed option.
Meilisearch: The Fastest Path to Working Search#
Meilisearch prioritizes ease of setup over fine-grained control. Typo tolerance, faceting, and instant-as-you-type results are on by default, and a recent hybrid search update adds vector capability. You can have it running in minutes from a single command.
The trade-off is depth of control. Custom ranking logic and relevance tuning are more limited than in Elasticsearch or Typesense.
It fits teams that want search that works well immediately rather than search that can be tuned to precise behavioral specifications.
OpenSearch: Elasticsearch Compatibility with an Open License#
OpenSearch is the Apache 2.0-licensed fork of Elasticsearch, maintained by Amazon after Elastic changed its licensing terms.
For teams that need Elasticsearch's full feature set --- query DSL, aggregations, ELK-compatible tooling --- but require an open source license or want to consolidate inside AWS, it's the most direct path.
Migration friction from Elasticsearch is low: the API is nearly identical and the index format is the same.
AWS OpenSearch Service offers a fully managed option. Self-hosted operational complexity is similar to Elasticsearch.
Pinecone: Pure Vector Search#
Pinecone is a purpose-built vector database focused on storing and retrieving high-dimensional embeddings at scale. It does not include keyword search.
The strength is fast, scalable vector similarity search, which is why it's a common choice as the dedicated retrieval layer in RAG application architectures.
If your use case is pure semantic retrieval --- embed the query, find similar vectors, hand results to an LLM --- Pinecone is built for that pipeline. If you also need keyword search alongside, you'll need to add a separate component.
Weaviate: Multimodal and Hybrid Retrieval#
Weaviate is an open-source vector database with native BM25 keyword search, multimodal data support (text, images, audio in the same index), and a modular architecture that lets you swap embedding models without re-indexing. Hybrid search is a first-class feature, not a plugin.
The query interface is GraphQL, which has a learning curve coming from Elasticsearch's JSON DSL.
Self-hosted production deployments typically run on Kubernetes; Weaviate Cloud offers a managed alternative.
Matching Your Constraints to the Right Tool#
Primary requirement Operational constraint Recommended option
Semantic search + source citations, fast deploy No dedicated search ops Denser Retriever
Elasticsearch compatibility, open license Engineering team available OpenSearch
Developer-friendly self-hosted structured search Some ops capacity Typesense
Fastest possible setup, front-end search UX Minimal ops desired Meilisearch
Pure vector search for RAG pipelines Prefer managed Pinecone
Hybrid search with multimodal data Engineering team for Kubernetes Weaviate
Maximum scale and full query DSL control Dedicated search engineering team Stay on Elasticsearch#
The "No-Cluster" vs. "Full-Control" Trade-Off#
The core tension in this decision is between handing operations off to someone else and keeping full control yourself.
Fully managed (no infrastructure) Light ops (simple self-host) Full ops (cluster management)
Tools Denser Retriever, Pinecone Typesense, Meilisearch, Weaviate Cloud Elasticsearch, OpenSearch, Weaviate self-host
Engineering requirement No search infra engineering Minimal --- single binary or container Dedicated search ops engineer(s)
Time to production < 1 day 1--3 days 1--3+ weeks
Semantic search Native Built-in hybrid Plugin or configuration required
Scale ceiling SaaS limits apply Single-node limits Horizontal scale, petabyte-capable#
Where to Start#
The best way to evaluate any of these is to run real data through it --- comparison tables only get you so far.
Denser Retriever supports self-serve registration, usage-based pricing, and no contracts. You can upload some of your team's actual documents or connect a test database, then run real queries to see relevance and recall in your own context.
Full use cases and implementation examples are at denser.ai/solutions/.
Common Questions About Denser Retriever#
Q1: How do we migrate data from Elasticsearch to Denser Retriever?
You don't need to move indexes. Denser Retriever connects directly to websites, PDFs, and databases through its API --- initial indexing typically takes minutes, which saves the migration overhead of traditional index transfers.
Q2: How does Denser Retriever's performance compare to Elasticsearch?
The two optimize for different things. Elasticsearch is strong on horizontal scale and high throughput. Denser Retriever's three-layer retrieval and re-ranker optimize for result relevance, particularly in natural language query scenarios.
Q3: If a team is already using a vector database, do they still need Denser Retriever?
If pure vector similarity for feeding context to an LLM is all you need, a standalone vector database is sufficient. If you need keyword precision matching, cross-source retrieval (web + PDFs + databases), and source citations together, Denser Retriever consolidates these into a single API instead of separate components.
Q4: What data sources does Denser Retriever support?
Websites (paste a URL for automatic crawling), documents (PDF, Word, Excel, Markdown, and more), and databases (via REST API). All sources are indexed in the same project and returned together at query time.
Q5: From a developer evaluation standpoint, what's the API design like?
Standard REST conventions, API key authentication, structured JSON responses containing answers, relevance scores, and source citations. SDKs and documentation are available after registering at denser.ai.
Q6: Can Denser Retriever and Elasticsearch coexist?
Some teams keep Elasticsearch handling logs, monitoring, and large-scale structured data search, while Denser Retriever handles knowledge scenarios that need semantic retrieval and source citations. The two solve different problems and often run side by side.