What is Retrieval-Augmented Generation (RAG)?

Artificial intelligence has been helping businesses with everything from simple customer queries to complex problem-solving. However, even the most advanced AI models sometimes fall short, providing answers that miss the mark.
That's where retrieval augmented generation (RAG) becomes beneficial. It improves the way AI models generate content by using real-time data.
An AI system like RAG not only relies on outdated information but actively searches for the latest and most relevant data to answer customer questions. It combines the extensive knowledge base of AI models with the accuracy of real-time data retrieval. This results in responses that are not only spot-on but also perfectly tailored to the context.
In this article, we'll explore how RAG works and its potential to transform how businesses use AI.
What is Retrieval Augmented Generation?#
Retrieval augmented generation is an advanced technique in artificial intelligence that improves the capabilities of large language models (LLMs) by incorporating external knowledge sources into their generative processes.
Unlike traditional LLMs, which generate responses based solely on their pre-trained knowledge, RAG retrieves relevant information from external databases or documents and uses this information to generate more accurate and contextually relevant responses.
This method ensures that the output is grounded in the latest and most authoritative data, making it particularly useful for applications requiring up-to-date information. When choosing embedding models for RAG, our comparison of open-source vs paid models shows that free alternatives can match Anthropic and Cohere performance.
Key Components of RAG Systems#
To fully understand RAG, it is important to break down its main components: the Information Retrieval (IR) system and the Natural Language Generation (NLG) model.
Information Retrieval#
The IR system uses advanced search algorithms to scan large datasets and find relevant information quickly. These algorithms employ semantic search techniques, which go beyond simple keyword matching to understand the context and meaning of queries. For a comparison of search platforms that support RAG, see our Elasticsearch alternatives guide. You can also learn how AI-native search engines use machine learning models for more intelligent retrieval.
RAG systems can retrieve data from multiple sources, including internal databases, online repositories, and real-time web searches. The quality and range of these data sources are critical to the system's effectiveness.
Natural Language Generation#
The NLG component relies on powerful language models, such as GPT-3, which are capable of generating human-like text. These models are trained on huge datasets, enabling them to create responses that are both coherent and contextually relevant. Businesses can also train ChatGPT on their own data for domain-specific applications.
NLG involves several techniques to ensure the generated text is relevant and accurate. This includes fine-tuning the model with domain-specific data and using advanced text generation algorithms.
Why Use RAG?#
RAG addresses several inherent limitations of LLMs, such as their reliance on static training data, which can lead to outdated or inaccurate responses. By integrating external knowledge bases, RAG enables LLMs to access real-time information, thus improving the relevance and accuracy of their responses.
This approach reduces the likelihood of misinformation and builds greater trust in the AI's outputs. Additionally, RAG allows organizations to control and update the knowledge sources, providing a more dynamic and adaptable AI solution.
4 Benefits and Use Cases of RAG#
If you combine real-time information retrieval with advanced NLG, it helps RAG systems provide more accurate, relevant, and contextually appropriate responses. Here are the key advantages that make RAG suitable for a wide range of applications across various industries.
- Cost-Effective Implementation
Using RAG is more budget-friendly than retraining large language models with new data. It lets you add new information without the hefty technical and financial expenses that come with extensive retraining.
- Current Information
RAG enables LLMs to provide the latest information by connecting to live data feeds, news sites, and other frequently updated sources. This capability ensures that the responses remain relevant and accurate, even as new information becomes available.
- Improved User Trust
Providing responses that include citations or references to authoritative sources can help RAG build user trust. Users can verify the information, leading to greater confidence in the AI-generated responses.
- More Developer Control
RAG offers developers the flexibility to change information sources and troubleshoot issues more effectively. It also allows for the restriction of sensitive information retrieval based on authorization levels, ensuring that the responses are appropriate for different contexts.
How Does RAG Work?#
Understanding the inner workings of RAG helps us appreciate its potential to improve AI-generated content. The RAG process involves several key steps:
Create External Data#
External data, which exists outside the LLM's original training data, is collected from various sources such as APIs, databases, or document repositories. This data is then converted into numerical representations using embedding language models and stored in a vector database, creating a knowledge library that the generative AI models can access.
Retrieve Relevant Information#
When a user query is received, it is converted into a vector representation and matched with the vector database to retrieve relevant documents. For example, in a smart chatbot application, if an employee asks about their annual leave, the system will retrieve policy documents and past leave records to answer questions.
Augment the LLM Prompt#
The retrieved data is added to the user input, creating an augmented prompt. This augmented prompt, which includes the original query and the relevant retrieved information, is then fed into the LLM to generate a response that is both informed and contextually accurate.
Update External Data#
The documents and their embeddings are regularly updated through automated real-time processes or periodic batch processing. This ongoing update process is important for maintaining the accuracy and relevance of the information retrieved by the RAG system.
Differences Between Prompting, Fine-Tuning, and RAG#
There are several ways to get the most out of language models. Three common techniques are prompting, fine-tuning, and RAG. Each one works differently and has its own advantages.
Prompt Engineering#
Prompt engineering involves crafting specific inputs or prompts to guide the model's responses. This method is user-friendly and cost-effective but limited by the model's pre-trained knowledge. It is best suited for general topics and quick answers.
Fine-Tuning#
Fine-tuning adjusts the model's parameters using additional data to improve performance on knowledge-intensive tasks. This approach provides high customization but is resource-intensive and requires significant computational power and expertise.
RAG#
RAG combines the strengths of retrieval and generation by using external knowledge bases to inform the model's responses. It balances the ease of prompting and the customization of fine-tuning, making it suitable for applications requiring dynamic and contextually rich outputs.
RAG allows for the integration of the most current and relevant information without the need for extensive retraining.
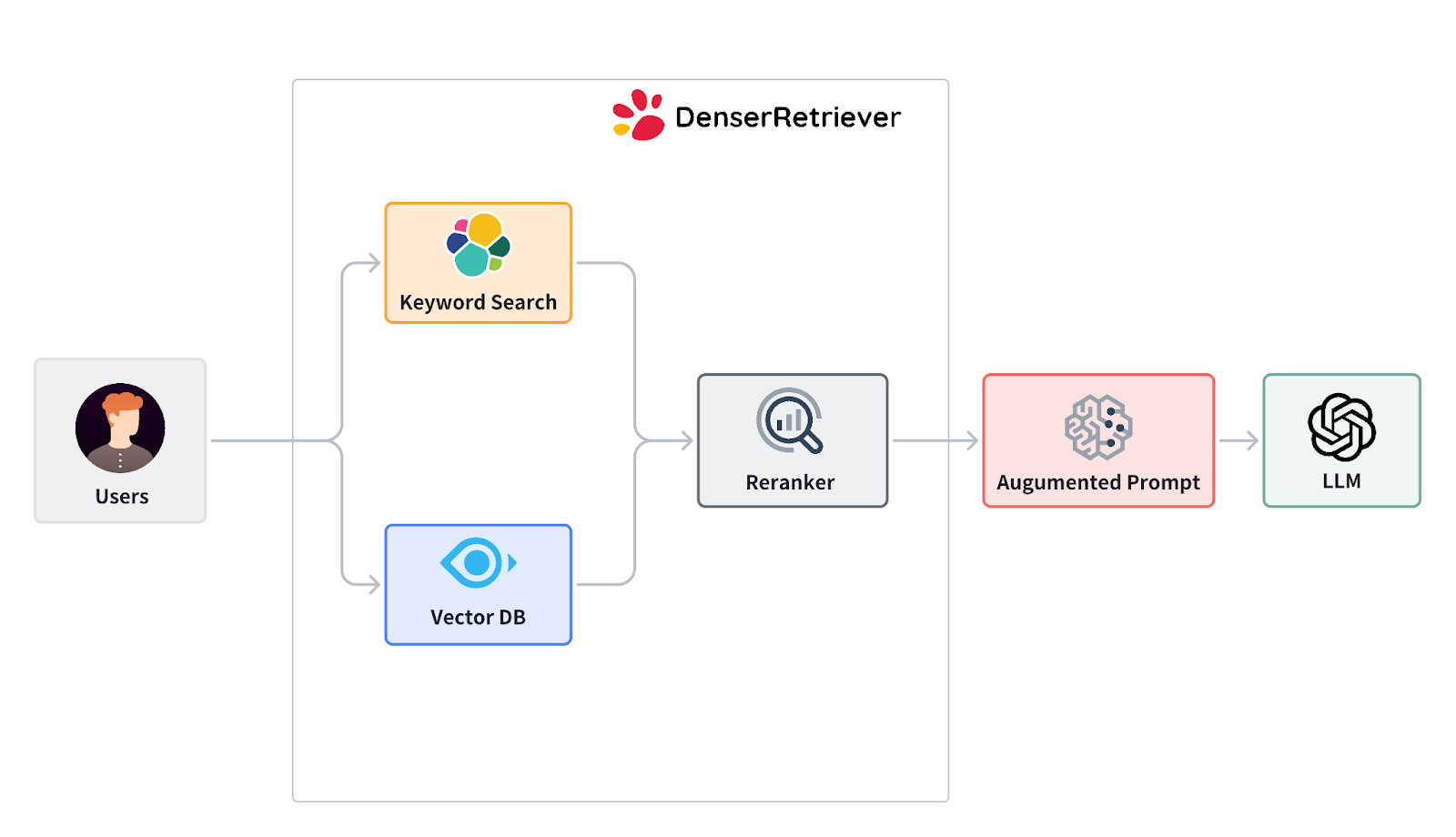
Denser Retriever Project#
The Denser Retriever project is a prime example of the power of RAG. This open-source initiative combines multiple search technologies into a single platform, using gradient boosting (xgboost) machine learning techniques to integrate keyword-based searches, vector databases, and machine learning rankers.
The result is a highly accurate search system that significantly outperforms traditional vector search baselines.
On the widely used MSMARCO benchmark dataset, Denser Retriever achieved a relative NDCG@10 gain of 13.07% compared to the best vector search baseline, demonstrating its superior performance and effectiveness. This remarkable improvement showcases the potential of RAG in enhancing the accuracy and relevance of search and retrieval systems. Experience this performance firsthand on the Denser Retriever platform.
For more information and to contribute to the Denser Retriever project, explore the following resources:
- GitHub Repository: Denser Retriever
- Blog: Denser Blog
- Documentation: Denser Retriever Documentation
Adopting RAG and supporting projects like Denser Retriever can significantly boost an organization's capabilities and the reliability of its AI systems. This ensures that they provide accurate, current, and contextually rich responses to user queries.
FAQs About Retrieval Augmented Generation (RAG)#
How is natural language processing involved in RAG?#
Natural language processing is a core component of RAG. NLP techniques are used in both the IR and NLG components to understand and generate human-like text. In the IR component, NLP helps in performing semantic searches. Meanwhile, in the NLG component, NLP enables the generation of coherent and contextually relevant responses.
What role does semantic search play in RAG?#
Semantic search plays a crucial role in RAG by enabling the retrieval component to understand the context and meaning of queries. This allows the system to fetch data that is more relevant to the user's intent rather than just matching keywords.
What is the difference between RAG and generative AI?#
Generative AI typically refers to AI models that generate content based on pre-existing data without retrieving additional information.
RAG, on the other hand, combines generative AI with information retrieval, allowing it to generate content that is informed by real-time data from external sources, leading to more accurate and relevant responses.