Enhancing LangChain with Denser Retriever


🎉 Thanks LangChain to feature Denser Retriever project in the official LinkedIn post. In this blog, we will discuss the importance of accurate and efficient information retrieval in AI applications and compare Denser Retriever with LangChain's vector store retriever. We will also explore the potential benefits of integrating Denser Retriever into LangChain framework to enhance the performance of AI applications.
What is AI Retriever?#
In the world of AI, a "retriever" is a tool used to sift through vast amounts of data to find information that is relevant to a user's query. Think of it as a highly intelligent search engine that helps AI systems understand and gather the exact information needed to answer questions effectively. The Retriever is the cornerstone of the Retriever Augmented Generation (RAG) framework, playing a crucial role in delivering an accurate and seamless experience in AI applications. A retriever is an interface that returns documents given an unstructured query. It is more general than a vector store.
LangChain Retrievers#
LangChain is a powerful framework that allows developers to build applications powered by large language models (LLMs). It provides the tools to harness the capabilities of LLMs while offering a structured approach to integrating various components such as chains, prompts, memory, and external data.
LangChain's retriever tutorials cover a broad range of topics including using a vector store to retrieve data, generating multiple queries to retrieve data, using contextual compression to compress the data retrieved, combining the results from multiple retrievers, generating multiple embeddings per document, retrieving the whole document for a chunk, using hybrid vector and keyword retrieval. The tutorials even cover niche topics such as reordering retrieved results to mitigate the "lost in the middle" effect and creating a time-weighted retriever.
LangChain mainly use vector store models to retrieve data. With LangChain's flexible framework, users can choose their favorite embedding models such as snowflake-arctic-embed-m and text-embedding-3-large. Below lists sample code to use LangChain's vector store retriever to retrieve documents from a text file.
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
loader = TextLoader("state_of_the_union.txt")
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(texts, embeddings)
retriever = vectorstore.as_retriever()
docs = retriever.invoke("what did the president say about ketanji brown jackson?")Users can refer to the LangChain documentation for more details on how to build and use retrievers in LangChain.
Denser Retriever#
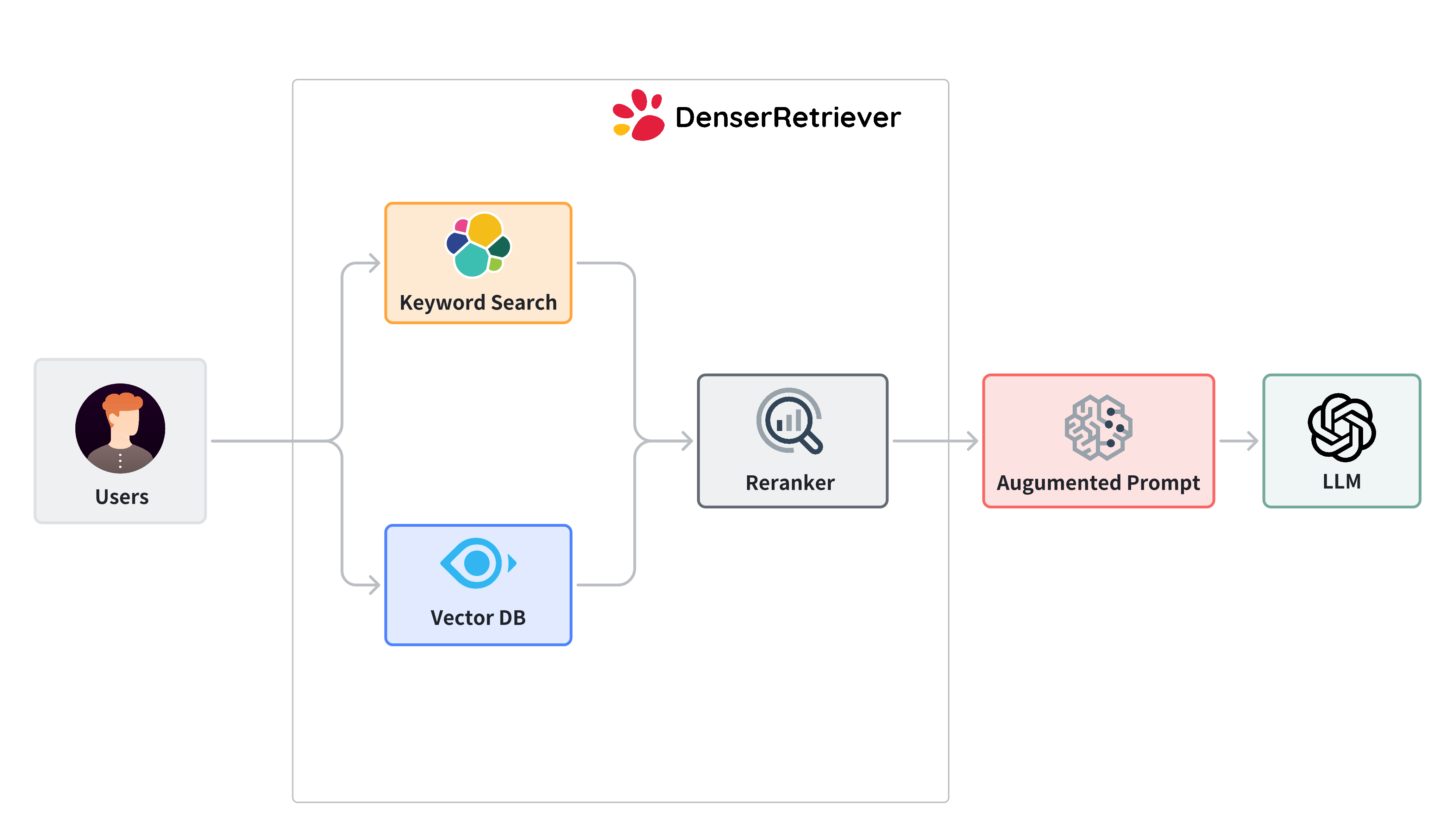
Given the broad coverage of LangChain retriever, the question is that what value does Denser Retriever bring to the table? The answer lies in the accuracy and efficiency of the retriever. Denser Retriever is a state-of-the-art (SOTA) retriever that leverages both dense and sparse representations to achieve superior performance in retrieving relevant documents. Explore the Denser Retriever platform for production-ready RAG implementations. By using dense embeddings, Denser Retriever can capture semantic relationships between documents and queries more effectively, leading to more accurate results. Additionally, Denser Retriever is optimized for speed and scalability, making it suitable for large-scale applications that require real-time retrieval of information.
Denser Retriever combines multiple search technologies into a single platform. It utilizes gradient boosting ( xgboost) machine learning technique to combine:
- Keyword search relies on traditional search techniques that use exact keyword matching. We use elasticsearch in Denser Retriever.
- Vector search uses neural network models to encode both the query and the documents into dense vector representations in a high-dimensional space. We use Milvus and snowflake-arctic-embed-m model, which achieves state-of-the-art performance on the MTEB/BEIR leaderboard for each of their size variants.
- A ML cross-encoder re-ranker can be utilized to further boost accuracy over these two retriever approaches above. We use cross-encoder/ms-marco-MiniLM-L-6-v2, which has a good balance between accuracy and inference latency.
Denser Retriever combines the keyword search, vector search and re-ranker effectively to provide optimal results. By combining these three components, Denser Retriever is able to deliver highly accurate and relevant results, making it an ideal choice for AI applications that require precise information retrieval.
Compare Vector Store and Denser retriever on SicFact dataset#
LangChain mainly use vector store models to retrieve data. In this section, we use the mteb/scifact dataset to compare the vector store retriever from LangChain and Denser Retriever. The dataset contains scientific claims and evidence sentences, which is a challenging retrieval task due to the complex nature of scientific language and the need for accurate information retrieval. Interested readers can refer to Denser Retriever training doc and github repository to replicate the experiment.
The scifact data set consists of three components: a query set, a passage corpus and a qrels file which annotates the relevance of passages for queries. With the following train_and_test.py command, we train a Denser Retriever using scifact training data and report the accuracy (NDCG@10) on scifact test dataset. NDCG@10 is a standard metric used to evaluate the performance of information retrieval systems. It measures the quality of the top 10 results returned by the system, with higher scores indicating better performance.
python experiments/train_and_test.py experiments/config_server.yaml mteb/scifact train test
Specifically, we use experiments/config_server.yaml as the config file (we need to configure hosts, users and passwords for Elasticsearch and Milvus), use mteb/scifact dataset, use the train split to train a xgboost model and test the trained model on test split data. If successful, we would get the vector database and Denser retriever accuracy in the following format.
| Model | NDCG@10 on SicFact |
|---|---|
| Snowflake arctic-embed-m-v1.5 | 73.16 |
| Denser Retriever | 75.33 |
The vector store uses snowflake-arctic-embed-m model, which achieves state-of-the-art performance on the MTEB/BEIR leaderboard for each of their size variants. The vector store model achieves an NDCG@10 score of 73.16, while the Denser retriever achieves an NDCG@10 score of 75.33. This result demonstrates that the Denser retriever outperforms the vector database in terms of accuracy, highlighting the value of using a state-of-the-art retriever like Denser Retriever in AI applications.
Compare Vector Store and Denser retriever on 15 MTEB retrieval datasets#
We now include more vector store models to compare with Denser Retriever. In addition, we conduct the comparisons on 15 MTEB retrieval datasets in stead of one dataset. These vector store models include snowflake-arctic-embed-m, Googlegecko, OpenAI text-embedding-3-large, and Nomicnomic-embed-text-v1.5. All vector store models have embedding dimensionality of 256. We list the NDCG@10 scores of these models on 15 MTEB retrieval datasets in the following table.
| Model | MTEB Retrieval |
|---|---|
| Snowflake arctic-embed-m-v1.5 | 54.2 |
| Googlegecko | 52.4 |
| OpenAI text-embedding-3-large | 51.7 |
| Nomicnomic-embed-text-v1.5 | 50.8 |
| Denser Retriever | 56.4 |
The experiments show that Denser Retriever outperforms all vector store models on the MTEB retrieval datasets, achieving an NDCG@10 score of 56.4. This result underscores the superior performance of Denser Retriever in retrieving relevant documents, making it an ideal choice for AI applications that require accurate and efficient information retrieval.
Next Steps#
In this article, we've explored the strengths of Denser Retriever and compared it with LangChain's vector store retriever. By leveraging dense embeddings and state-of-the-art models, Denser Retriever offers superior accuracy and efficiency in retrieving relevant documents.
As AI applications continue to evolve, the need for accurate and efficient information retrieval becomes increasingly important. Thanks LangChain to feature Denser Retriever project in the official LinkedIn post. To better serve LangChain community, we plan to integrate Denser Retriever into LangChain framework, providing users with a powerful tool to enhance the performance of their applications. Stay tuned for more updates on this exciting collaboration!