Denser Search & Chat: Architecture & Implementation

Introduction#
Large Language Models (LLMs) have quickly changed our daily life. One of the most important applications are due to the Retrieval Augmented Generation (RAG). Instead of directly asking question to LLMs (such as ChatGPT and Bard), RAG first runs a search via a retriever (R in RAG) for your query. It then feeds the search results, along with the query, to a LLM to generate (G in RAG) the final response. In RAG applications, the retriever plays a key role to ensure the search results are highly relevant to a query, and therefore ensures the LLM's results are accurate and grounded in the search results, effectively mitigating the risk of hallucinations.
In this blog, we present how we built and deployed Denser Search and Chat as a RAG solution. We cover both the architecture and implementation parts. We not only present optimal and practical solutions to RAG, we also emphasize the practicality of deploying an end-to-end solution in frugality.
Architecture#
The term "Retrieval-Augmented Generation" (RAG) was first introduced in the paper entitled Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. However, the Retrieval and then modeling workflow has long been adapted in both research and industry. For example, prior to the rising of the ChatGPT, Amazon Kendra has utilized a retriever to search relevant results for a given query, and then use the search results to provide precise factual answers for queries.
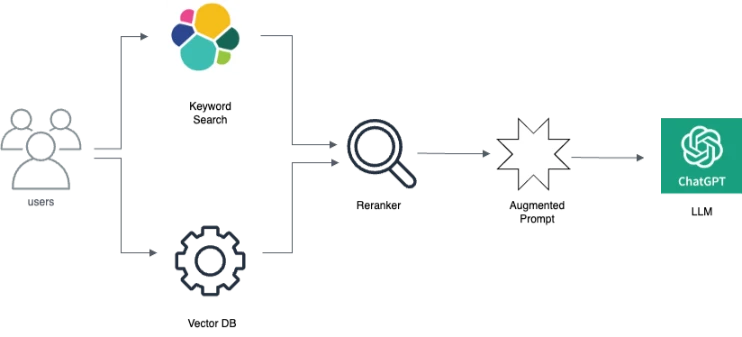
The are two main types of retrievers: Keyword-based Search and Vector Database (previously named Denser Retriever). Keyword-based search (such as ElasticSearch) relies on traditional search techniques that use exact keyword matching. It operates by identifying and matching specific words or phrases from the query to those in the database documents. Vector Database uses neural network models to encode both the query and the documents into dense vector representations in a high-dimensional space. The retrieval is then based on the proximity of these vectors, often measured by cosine similarity or dot product. In summary, while keyword-based search excels in situations with clear and direct keyword overlap, Vector DB offers a more sophisticated approach, capable of understanding and responding to the semantics and context of the query, thereby expanding the range and relevance of the retrieved information.
In addition, a query passage re-ranker can be utilized to further boost accuracy over these two retriever approaches above. Specifically, for any query and passages retrieved by keyword-based search or Vector DB, we apply a BERT style re-ranker to score the relevance between queries and passages.
We finally feed the query and retrieved/re-ranked passages to a LLM such as ChatGPT, with an optimized prompting to get the final answers.
Implementation#
We implement the aforementioned Denser Search and Chat architecture on AWS services. The following diagram illustrates implementation of Denser inference.
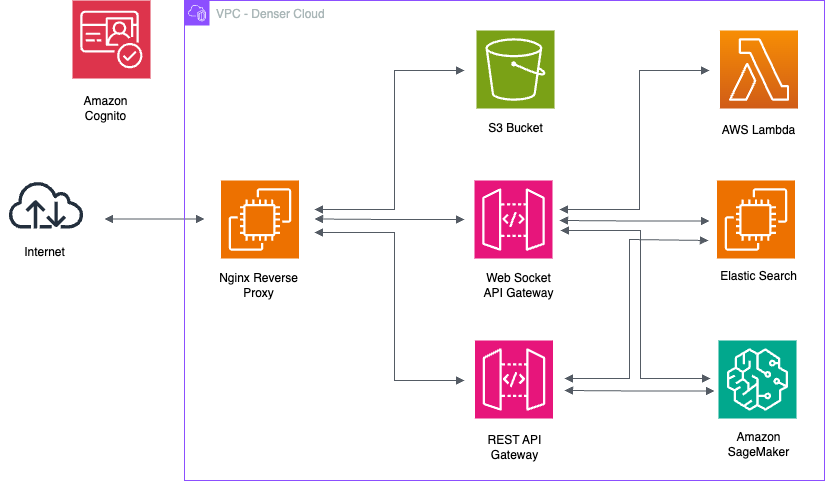
- Nginx Reverse Proxy provides routing to different components in Denser VPC (purple box).
- S3 buckets stores static web content, which includes html, css, js, and images etc.
- WebSocket API Gateway points to Elastic Search, Amazon SageMaker inference, and Lambda chat services. AWS manages auto scaling of SageMaker and Lambda functions.
- REST API Gateway points to Elastic Search and Amazon SageMaker inference services.
Denser training provides a pool of SageMaker trainers to asynchronously build retrievers for provided websites or files. In case of building a chatbot from files, user uploaded files are stored in an S3 bucket. Building is asynchronous in a way that SageMaker acknowledges user's request immediately, and it continues the retriever building in the backend. User can then periodically query build status until the building process is complete.
Denser's Use Cases and Advantages#
Denser's Search and Chat can be applied to the following applications:
- Website Search and Chat: Transform site interactions with AI-Powered Search and Chat.
- Enhanced Technical Support: Gain in-depth insights from documents for technical doc support.
- Superior Customer Service: Revitalize your customer interactions with smart systems.
- Proactive Lead Generation: Master the art of generating leads from your website.
Denser brings the following advantages:
- Efficiency & Scalability: Build intelligent AI search & chat systems over hundreds of thousands web pages.
- Exceptional Accuracy: Deliver precise answers and cite source documents, significantly minimizing hallucinations.
- Advanced Search Functionality: Offer document and text segment search results in conjunction with AI responses.
- Cost-Saving Intelligence: continuous 24/7 assistance and significant cost reduction.
Building and Deploying Denser Search and Chat#
We provide a comprehensive documents to guide how to build and deploy Denser Search and Chat service. The deployment includes integrating your chatbot to your website as a widget, an embedded iframe, or pass a user’s query to Denser REST API to get responses.
Conclusions#
In this blog, we presented the model architecture and implementation for Denser Search and Chat. We also outlined Denser's use cases and advantages. Finally, we showed how to build and deploy Denser search and chat service. We hope you enjoy reading this. Should you have any feedback, please feel free to reach out to support@denser.ai.