Anthropic Embeddings vs Open-Source: 5 Free Cohere Rerank Alternatives That Match Paid Models

TLDR: DenserRetriever is a retriever platform which supports keyword search, vector search and reranker and it provides efficient solutions to build RAG applications. We benchmarked the Anthropic Contextual Retrieval dataset in DenserRetriever and reproduced impressive results! Our innovative integration of Elasticsearch + vector search powers large-scale, industrial RAG deployments. 🚀 💡 Even better? Open-source models matched or outperformed the accuracy of paid ones, offering a cost-effective solution without compromising performance. Say goodbye to high costs and hello to scalable, high-accuracy AI!
Introduction#
Retrieval-Augmented Generation (RAG) is a powerful technique to enhance AI model responses by retrieving relevant information from a knowledge base and appending it to the user's input. This technology powers features like chat with PDF, where users ask questions and get cited answers from their documents. Despite its effectiveness, traditional RAG implementations often strip away important context when encoding information, which can result in lower retrieval accuracy and suboptimal performance on downstream tasks.
Anthropic, in their blog post Introducing Contextual Retrieval and cookbook, proposed a novel method known as Contextual Retrieval, which improves the accuracy of the retrieval process within the RAG framework. This method retains the necessary context during the encoding step, ensuring more relevant information is retrieved, thus significantly improving downstream task performance.
In this blog, we first reproduce Anthropic’s contextual retrieval experiments in Denser Retriever. We then replace the paid API with open-source (free) models and show that open-source models can achieve accuracy levels equal to or better than those of paid models. This is crucial for cost-sensitive production environments where maintaining accuracy while minimizing expenses is essential. Our experiment directory can be found here.
Dataset#
The dataset used in this experiment is described in Anthropic's blog post Introducing Contextual Retrieval and is available in their Anthropic Cookbook. The dataset contains 248 queries and 737 documents.
Preparing Dataset for Denser Retriever#
To use this dataset in Denser Retriever experiments, we first copy the original data from Anthropic cookbook to original_data directory. We then run the following command to prepare the data:
python experiments/data/contextual-embeddings/create_data.py
This generates two datasets:
- data_base: The original dataset provided by Anthropic.
- data_context: An augmented version of the dataset with additional contextual information, as described in Anthropic's blog post.
Each dataset contains:
- A query file (queries.json)
- A document file (passages.jsonl)
- A relevance file (qrels.jsonl)
The key difference between these datasets is that the data_context version contains augmented document contexts, which are provided by the Anthropic API. We provide data_context so users can run experiments without needing to call the Anthropic API.
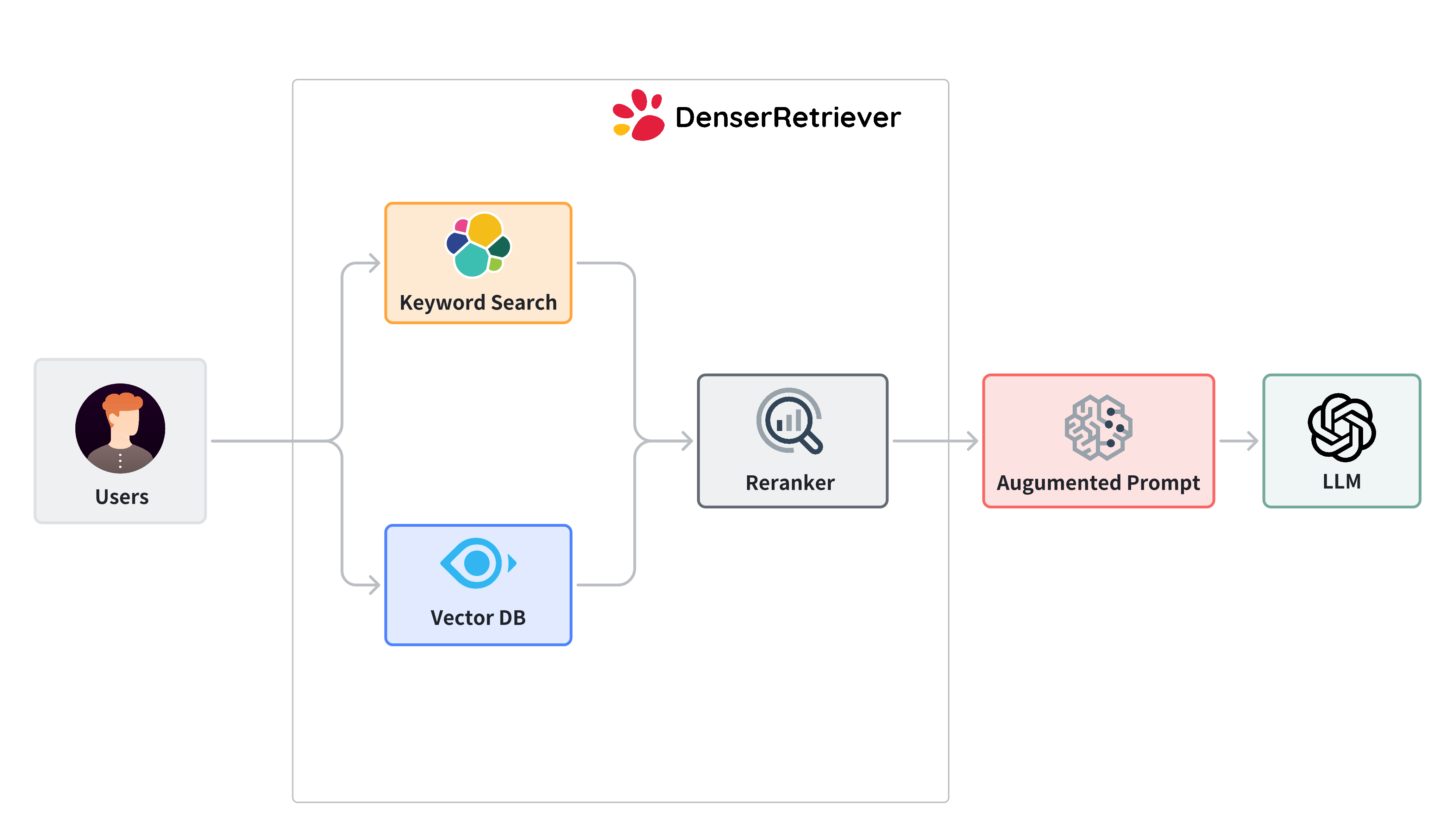
Denser Retriever#
Denser Retriever is a retriever platform which supports keyword search, vector search and re-ranker effectively to provide optimal results. Our experiments on MTEB datasets show that the combination of keyword search, vector search and a reranker via an xgboost model can significantly improve the vector search.
Reproducing Anthropic Contextual Retrieval Experiment#
Using Base Dataset (Without Context)#
We first evaluate Denser Retriever on the data_base dataset. This is done by running the following command:
python experiments/train_and_test.py anthropic_base test test
The experiments/train_and_test.py script can be found here. In this experiment, anthropic_base is the name of the dataset, and the two test arguments refer to the training and test splits, which are identical in this case.
Following Introducing Contextual Retrieval, we uses the Voyage voyage-2 API for vector embeddings and the Cohere rerank-english-v3.0 API for re-ranking.
The following results are obtained:
| Method | Recall@20 |
|---|---|
| Keyword Search (BM25) | 70.48 |
| Vector Search (Voyage) | 90.06 |
| Reranker (Cohere) | 94.15 |
| Keyword+Vector+Reranker (Denser Retriever) | 94.24 |
Our results, including Keyword Search, Vector Search and Reranker, match the numbers reported in the Anthropic Cookbook. Specifically, the Recall@20 metric for vector search is consistent with the Cookbook’s result of 90.06. The reranker reranks the results from both Keyword Search and Vector Search and it further improves the recall to 94.15. The Keyword+Vector+Reranker method is a novel method proposed in Denser Retriever. It uses a lightweight xgboost model to score the query and document relevance. The Keyword+Vector+Reranker method achieves a Recall@20 of 94.24, outperforming the individual components. It is worth noting that Keyword+Vector+Reranker introduces less than one millisecond of latency per query, making it suitable for real-time applications.
Using Contextual Dataset#
Next, we reproduce the Anthropic context retrieval experiments with Denser Retriever by running the following command:
python experiments/train_and_test.py anthropic_context test test
The results are summarized below:
| Method | Recall@20 |
|---|---|
| Keyword Search (BM25) | 89.26 |
| Vector Search (Voyage) | 94.48 |
| Reranker (Cohere) | 96.10 |
| Keyword+Vector+Reranker (Denser Retriever) | 95.69 |
Similar to the original Anthropic experiment, we observe that the contextual augmentation significantly improves the performance of keyword search, with Recall@20 increasing from 70.48 to 89.26. Vector search also benefits from the augmented contexts, with recall improving from 90.06 to 94.48. The reranker further boosts the recall to 96.10, showcasing the value of adding reranker on top of Keyword and Vector search. We note that the Keyword+Vector+Reranker method in Denser Retriever does not lead to a boost over Reranker, possibly due to the fact that Cohere rerank-english-v3.0 Reranker performs significantly better than both Keyword search and vector search.
Contextual Experiments with Open-Source Models#
In either the base experiment or the experiment with augmented context, the Voyage API model cost several cents, and the Cohere reranker model API cost around $1. The cost can increase significantly if the retrieval corpus becomes large (remember, we only have 248 queries and 737 documents). Denser Retriever offers the flexibility to replace these paid models with open-source models, reducing overall costs without sacrificing accuracy.
We now replace the paid Voyage and Cohere models with open-source models and evaluate their performance. Specifically, we choose the BAAI/bge-en-icl embedding model and the jinaai/jina-reranker-v2-base-multilingual reranker model from Huggingface MTEB Leaderboard as free alternatives to the paid models. To do this, we modify the train_and_test.py script as follows:
embeddings=BGEEmbeddings(model_name="BAAI/bge-en-icl", embedding_size=4096),
reranker=HFReranker(model_name="jinaai/jina-reranker-v2-base-multilingual", top_k=100, automodel_args={"torch_dtype": "float32"}, trust_remote_code=True),We achieve the following results:
| Method | Recall@20 |
|---|---|
| Keyword Search (BM25) | 89.26 |
| Vector Search (BAAI) | 94.55 |
| Reranker (Jinaai) | 96.30 |
| Keyword+Vector+Reranker (Denser Retriever) | 96.50 |
The open source model bge-en-icl slightly outperforms the paid Voyage model voyage-2 in terms of Recall@20 (94.55 vs. 94.48). In addition, the open source model jinaai/jina-reranker-v2-base-multilingual outperforms the paid Cohere rerank-english-v3.0 reranker model (96.30 vs 96.10). Finally the Denser Retriever Keyword+Vector+Reranker boosts the final Recall@20 to 96.50. This demonstrates that open-source models can deliver accuracy levels better than paid models, offering a cost-effective solution without compromising performance.
Conclusion#
We reproduced Anthropic Contextual Retrieval experiments in Denser Retriever. Our implementation integrates both Elasticsearch and vector search, which are essential for large-scale, industrial-grade deployment of the RAG framework. These retrieval techniques power practical tools like AI PDF readers and document analysis platforms. Our experiments demonstrate that open-source models can deliver accuracy equal to or better than paid models, offering valuable flexibility in cost-sensitive production environments where maintaining high accuracy while minimizing expenses is critical.